
Data science project can be a challenging but rewarding process. By following the steps we can use in this blog, you can work through the project in an organized and effective way, and ultimately arrive at a solution to your problem. Previously, we wrote blogs on many machine learning algorithms (Classification, Predication) as well as […]
data science
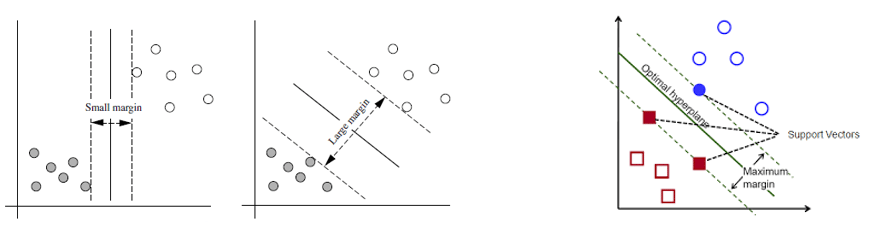
Mathematics Behind Support Vector Machine
Support Vector Machine is supervised machine learning algorithm. In this blog, we are going to discuss how mathematically support vector machine works. We will also discuss the types of SVM and how to implement it in Python. So, let’s get started. In the past, we have authored blog posts covering a wide range of topics, […]

Different Method of Model Evaluation(Part-1)
Accuracy is a metric that is used to evaluate the performance of a model on a classification task. It is the fraction of correct predictions made by the model on a data set, expressed as a percentage. For example, if a model makes 90 correct predictions out of 100, its accuracy is 90%. Previously, we […]

How to do Preprocessing of Dataset Before Applying Machine Learning Algorithms
Load the dataset First, import the packages required to continue. import pandas as pd import numpy as np import matplotlib.pyplot as plt %matplotlib inline Read the dataset using Pandas Read previously loaded data and store it in a variable named df, display the first few rows with head(), by default head() will return first 5 […]

Taking Data Apps into WebApp: Using Streamlit, Plotly, and Python
Introduction From the past 2 stories of a data and its journey to confess the insights, we have explored several areas and to point out few: We have done EDA based on descriptive and inferential part of the statistics to find strong evidences, relationships and facts about the data. We used some of valuable insights […]
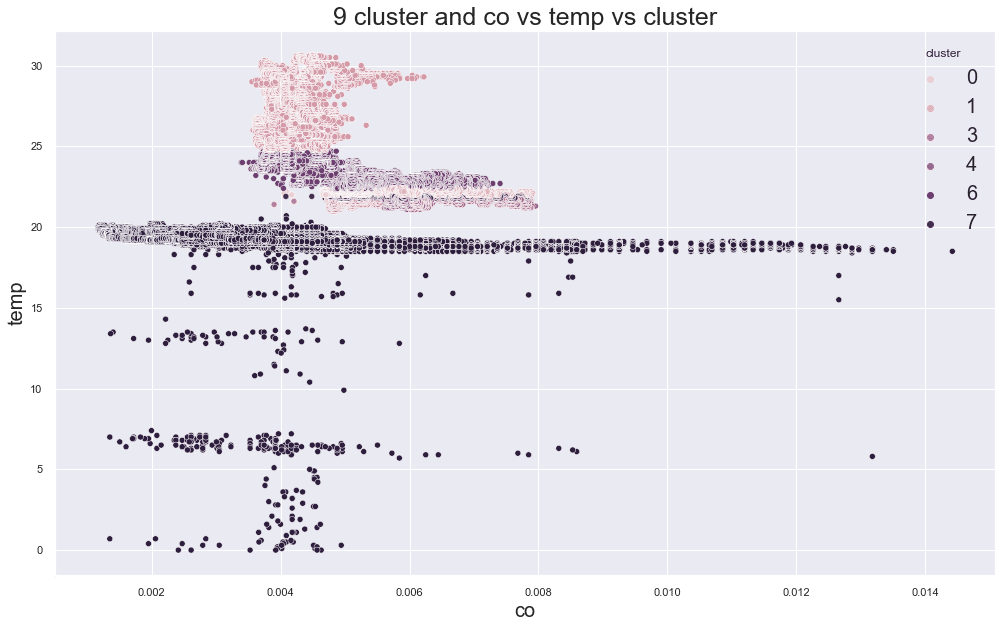
Beyond and Within EDA: Taking EDA into Modelling
Beyond and Within EDA Introduction This blog is the continuation of the previous blog post A General Way of Doing EDA. Please follow that before reading this blog. Once we got the knowledge of the data like its properties and features, we can move ahead by taking that knowledge to make some sort of inference. […]
Introduction to Probability for Data Science: Getting Started
Introduction Hello there welcome to the new blog series about Probability in the Data Science field. Here in this blog, we will start from basic concepts needed in using Probability in some datasets. This blog is going to be very short and basic yet informative. Probability is all about measurement of some event’s occurrence. We […]