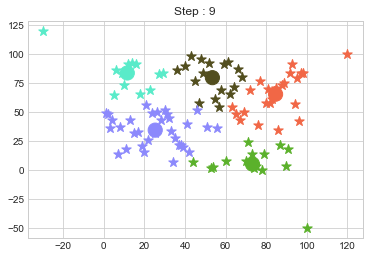
DBSCAN is an example of clustering algorithm. Clustering is the process of organizing a collection of concrete or abstract things into classes of related objects. A cluster is a group of data objects that are distinct from the objects in other clusters yet comparable to one another within the same cluster. There are various example […]
clustering
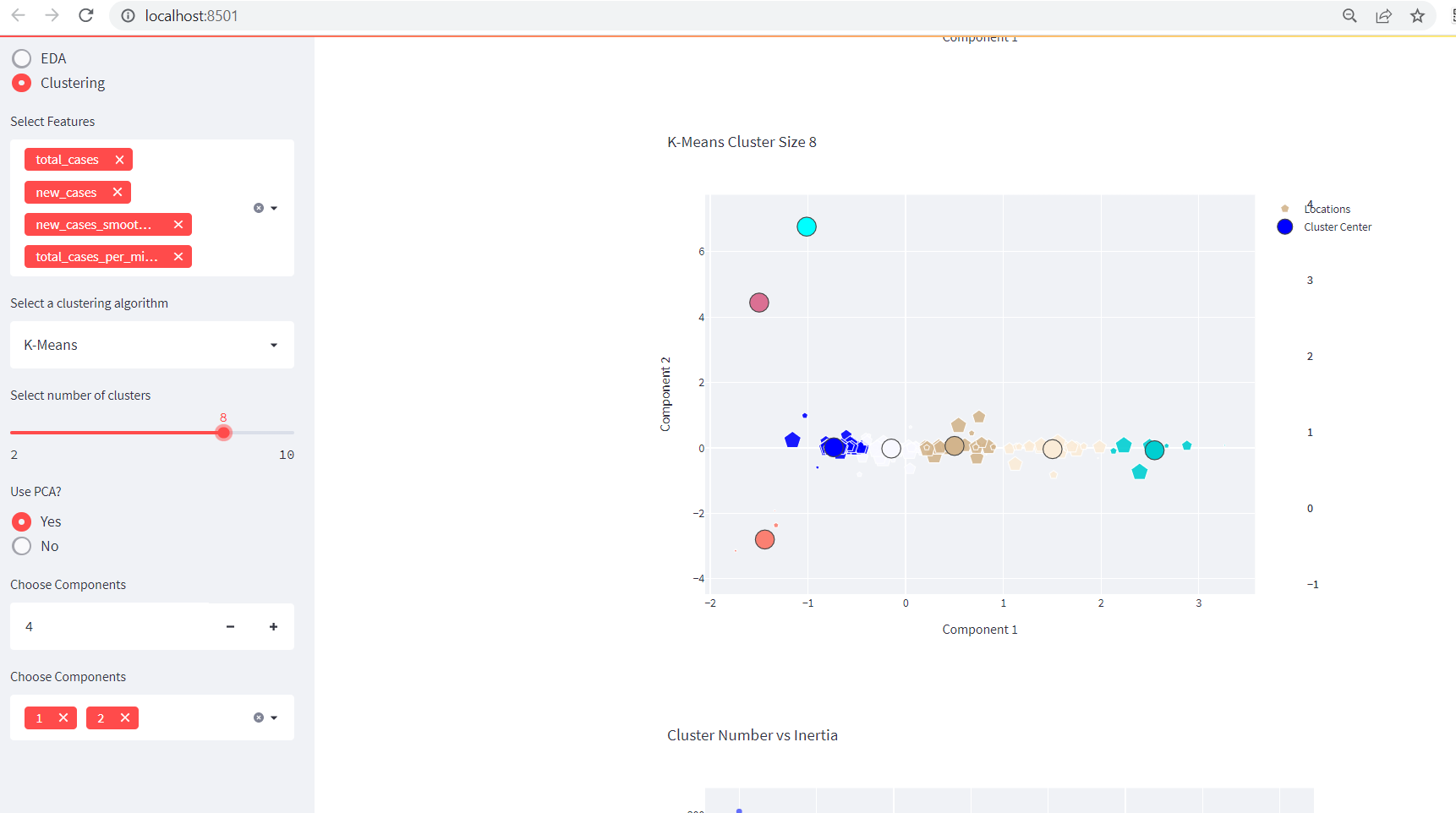
Creating Awesome Data Dashboard with Plotly in Streamlit: Clustering
This is a continuation of our previous blog entitled as Creating Data Dashboards With Streamlit and Python. Adding A Clustering Functionality Before diving into the clustering functionality in our existing app, please make sure you are following previous part. Or you can grab all the codes from below: import streamlit as st import numpy as […]

K Medoids Clustering from Scratch in Python
K Medoids Clustering is a clustering algorithm, have you tried to write it from scratch in Python? But before that, if you are also looking for other algorithms from scratch then please follow along: Linear Regression from Scratch Logistic Regression from Scratch Logistic Regression with Different Loss Functions PCA from Scratch K-Means Clustering from Scratch […]
K means Clustering in Python from Scratch
K means Clustering in Python from Scratch Introduction K means clustering is very simple type of unsupervised learning. Which is used to solve clustering problem. Using this algorithm we can easily classify given data point in given numbers of clusters (k). To do so we should first find number of cluster. In k mean cluster […]