Auto-encoders from scratch will be done over the concept of Neural Network from Scratch that I already did. You can find it on my following blogs.
I also have written Run Length Encoding from Scratch and you can give it a try if you'd like to.
I started to write this blog in May 2020 but since I already wrote the above two blogs, I felt that why bother training another model from scratch. But in November 2022, I got the following email from a reader and I thought that could be helpful to someone.

I really feel grateful that the blogs I wrote after failing an interview question Working mechanism of Convolutional Neural Network are helpful. If I have to write Neural Networks from Scratch again then I would have written it with easier and smaller codes. I feel that there are many things I have written in a horrible way 😜.
Introduction
Before going into auto-encoders from scratch, let me write something fundamental about it.
- Auto-encoders are nothing but a sequence of neural networks which basically has the same output as the input.
- Auto-encoders are trained to reach one thing that Deep Learning engineers hate, i.e. over-fitting.
Why do we call it encoder? Well it's because it turns our data into some weird form and then could turn that weird form into a somewhat original form. In Cryptography, we use plain text with some key to cipher the data to receive data in a non-readable format to protect it from unwanted readers. And we use some key to decipher that text to its original form. An Auto-encoder also has that ability (or concept only). In Cryptography, we can have two parts, one Encoder and another is Decoder. One part encodes data and another part decodes data from encoded data to give original data. Similarly, Auto-encoder is made up of two logical parts, Encoder and Decoder. Encoder is a small part of this whole network which receives inputs and processes and gives encoded form of input. Then another part Decoder receives that encoded form of input and processes to return the original form. The right question here will be where is the encryption key? There is not any. The encryption key in this model is the weight or parameters of a model.
In normal ML training, we do not want a model to be over-fitted or under-fitted. But in Auto-encoder, it's better to be over-fitted. Because we want our neural network to remember some information.
Applications
I am no expert to write a lot about the possible application of over-fitting but let me write some based upon my experience in real examples:
- Auto-encoders are powerful (kind of) to encode data and thus could be use to encrypt information. But it will be applicable only if there is a powerful decoder as well.
- What if we have a powerful auto-encoder that was trained on a series of our images? The overall size of images is huge because they were all captured with a really high quality camera. We can train an auto-encoder with many parameters and over-fit them to learn every image possible. Now we can have a very small output of the encoder and save that into the simple CSV file and delete the images. What is important here is storing the parameters and architecture of the model. If we want to view some image, we could simply pass a few bytes of encoded data to decoder and view the original image. Just my thoughts though!
- Conversion of Grayscale to RGB can be also done using Auto-encoders and you can find one that I did too.
Coding Part
Since auto-encoders are made up of a sequence of neural networks, auto-encoders from scratch simply means neural networks from scratch and here my coding goal will be to use my already created Neural Network module from scratch. Please find the codes in my GitHub repository below:
Importing Packages
I named my package Quark. Fancy isn't it? We need to import layers and Sequential form Stackker.
from quark.layers import *
from quark.Stackker import Sequential
import pandas as pd
import matplotlib.pyplot as pltGetting Data
To get the minst data, we are going to use Keras. I feel it is easy.
from keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()Pre-process Data
Let's preprocess data by reshaping and normalizing.
x = x_train.reshape(-1, 28 * 28) /255
# x = (x-x.mean(axis=1).reshape(-1, 1))/x.std(axis=1).reshape(-1, 1)
y = pd.get_dummies(y_train).to_numpy()
xt = x_test.reshape(-1, 28 * 28) /255
# xt = (xt-xt.mean(axis=1).reshape(-1, 1))/xt.std(axis=1).reshape(-1, 1)
yt = pd.get_dummies(y_test).to_numpy()Create and Train a Model
We will create a model with 3 layers. One will be input and then there will be a second layer and the final output layer. For us the first two layers could be the encoder and the last one could be decoder. But it is not necessary to divide like that. We will train for only 10 epochs with below hyper-parameters.
m = Sequential()
m.add(FFL(784, 10, activation='sigmoid'))
m.add(FFL(10, 10, activation="relu"))
m.add(FFL(10, 784, activation='sigmoid'))
m.compile_model(lr=0.001, opt="adam", loss="mse")
m.summary()
m.train(x[:], x[:], epochs=10, batch_size=32, val_x=xt[:], val_y = xt[:]) Input Output Shape Activation Bias Parameters
Layer Name
Input Layer 784 10 sigmoid True 7850
FFL1 10 10 relu True 110
Out Layer(FFL) 10 784 sigmoid True 8624
Total Parameters: 16584
Validation data found.
Total 60000 samples.
Training samples: 60000 Validation samples: 10000.
Total 1875 batches, most batch has 32 samples.
Epoch: 0:
Time: 97.376sec
Train Loss: 0.0674 Train Accuracy: 0.1443%
Val Loss: 0.0675 Val Accuracy: 0.1441%
Epoch: 1:
Time: 92.235sec
Train Loss: 0.0641 Train Accuracy: 0.1905%
Val Loss: 0.0642 Val Accuracy: 0.1887%
Epoch: 2:
Time: 83.891sec
Train Loss: 0.0611 Train Accuracy: 0.4515%
Val Loss: 0.0611 Val Accuracy: 0.4463%
Epoch: 3:
Time: 78.168sec
Train Loss: 0.0597 Train Accuracy: 0.6552%
Val Loss: 0.0595 Val Accuracy: 0.674%
F:\Desktop\Algorithms\quark\functions.py:23: RuntimeWarning: overflow encountered in exp
return 1 / (1+np.exp(-x))
Epoch: 4:
Time: 253.916sec
Train Loss: 0.0593 Train Accuracy: 0.7657%
Val Loss: 0.059 Val Accuracy: 0.7764%
Epoch: 5:
Time: 170.761sec
Train Loss: 0.0589 Train Accuracy: 0.7747%
Val Loss: 0.0586 Val Accuracy: 0.7738%
Epoch: 6:
Time: 166.393sec
Train Loss: 0.0582 Train Accuracy: 0.7798%
Val Loss: 0.058 Val Accuracy: 0.7837%
Epoch: 7:
Time: 149.165sec
Train Loss: 0.0576 Train Accuracy: 0.8639%
Val Loss: 0.0573 Val Accuracy: 0.8647%
Epoch: 8:
Time: 176.71sec
Train Loss: 0.0571 Train Accuracy: 0.9385%
Val Loss: 0.0568 Val Accuracy: 0.936%
Epoch: 9:
Time: 147.613sec
Train Loss: 0.0566 Train Accuracy: 0.9673%
Val Loss: 0.0564 Val Accuracy: 0.9618%It took my machine 23min to complete the above code and maybe this machine is old as well as my code. The accuracy was low but it doesn't matter much in Auto-encoders. Only thing that matters is loss and loss is decreasing slowly.
Input vs Output
We trained a model but was it strong enough to predict? Let's figure it out.
fig, axes = plt.subplots(nrows=2, ncols=10, sharex=True, sharey=True, figsize=(20,4))
in_imgs = xt[:10]
reconstructed = m.predict(in_imgs)
for images, row in zip([in_imgs, reconstructed], axes):
for img, ax in zip(images, row):
ax.imshow(img.reshape((28, 28)), cmap='Greys_r')
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
fig.tight_layout(pad=0.1)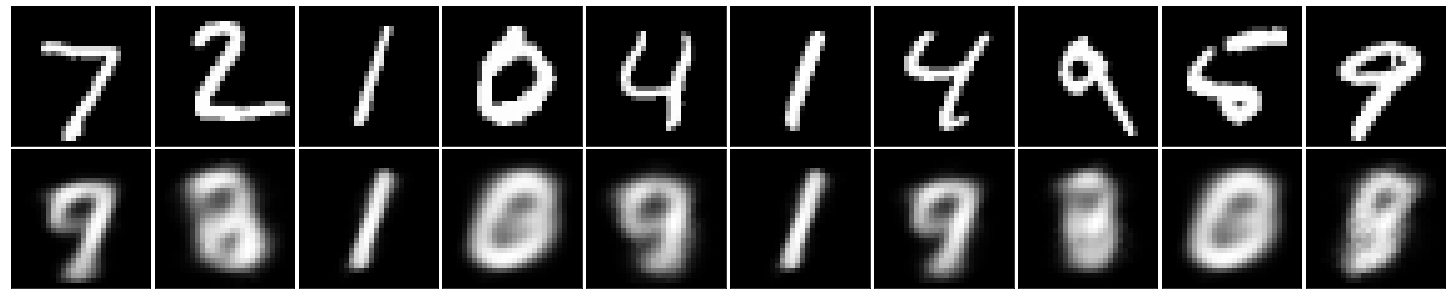
It seems that our model was able to predict what we can guess but it still is not okay! Maybe it could do better after training for more epochs but I would like to conclude it here.
Conclusion
We were able to train a simple Autoencoder from Scratch and see the results and I hope you found this to be useful.