CNN with Keras is easiest way to create CNN (Convolutional Neural Networks. But Why? Images I used in this blog are not owned by me and the full credit goes to the author of images. This blog was written in 2019 but I forgot to publish it that time and does not contain everything.
Why keras?
- Because its like drag and drop for Neural Networks.
- No more headache of mathematical complexity
- Can customize layers and do training easily.
- Has great preprocessing APIs as well as data generators.
What is CNN
The answer to this question has been already given by me in following blogs:
- [Writing Image Processing Codes from Scratch in Python](): Where I have written some codes to do read, write, convolve images.
- [Convolutional Neural Networks from Scratch in Python](): Made somewhat like keras class. This blog is first page of google search with query
cnn from scratch.
In simple words, CNN is mainly a image processing neural networks but can be used for other purposes also.
Why CNN?
- CNN has filters or kernel as learning parameters. Unlike simple neural nets, CNN uses very few parameters. In fact, parameters are shared!
- CNN handles feature extracting from images very efficiently.
Basic Terms in CNN
- No. channels: ex RGB, Grayscale
- Filters: each filter gives a filtered image ie. feature map
- Size of filters: it is a square matrix which shape is less than image
- Stride: value with which we will skip the convolution
- Padding: concept of working with edges
Lets see the visualization:
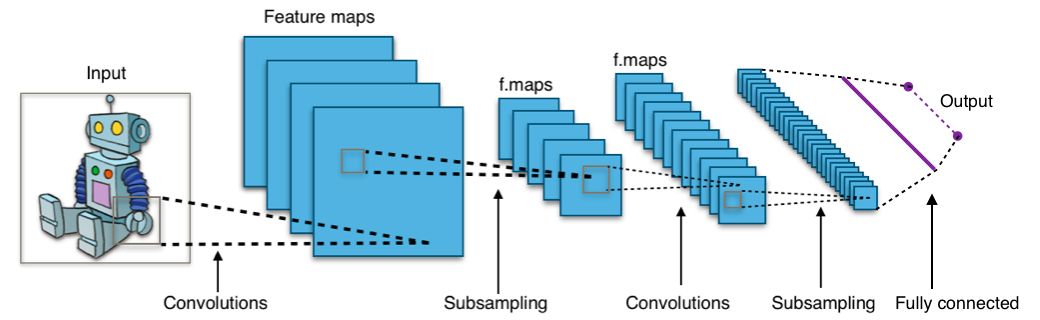
What does normal CNN include?
Normal CNN includes below layers:
- One input layer
- One output layer
- One or more convolutional layer
- One or more Max-pooling layer
- Some dropout layer
- One flatten layer
- One or more dense layer
- Some normalizing layers
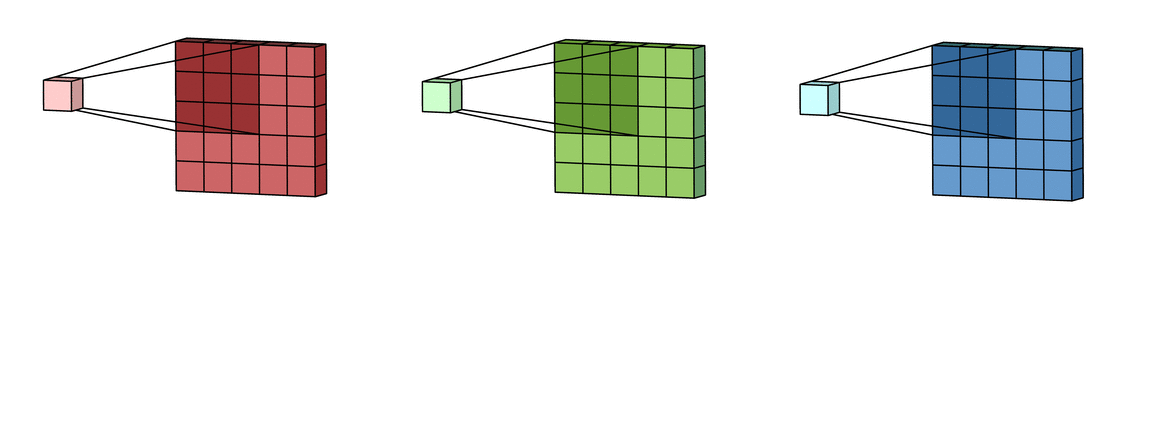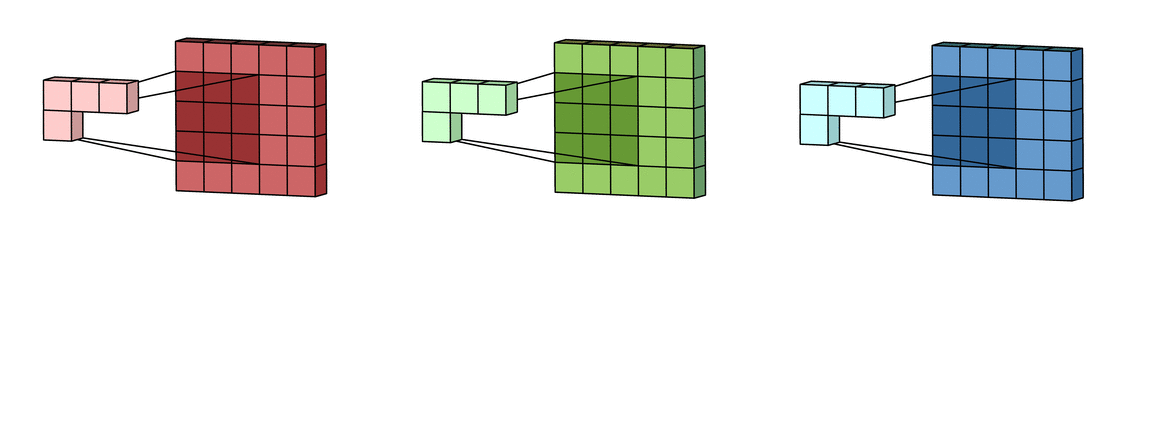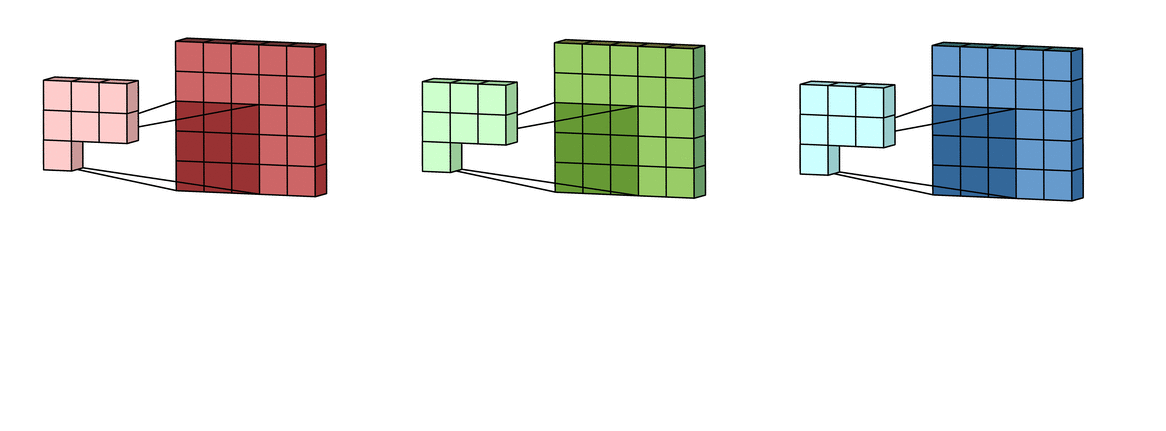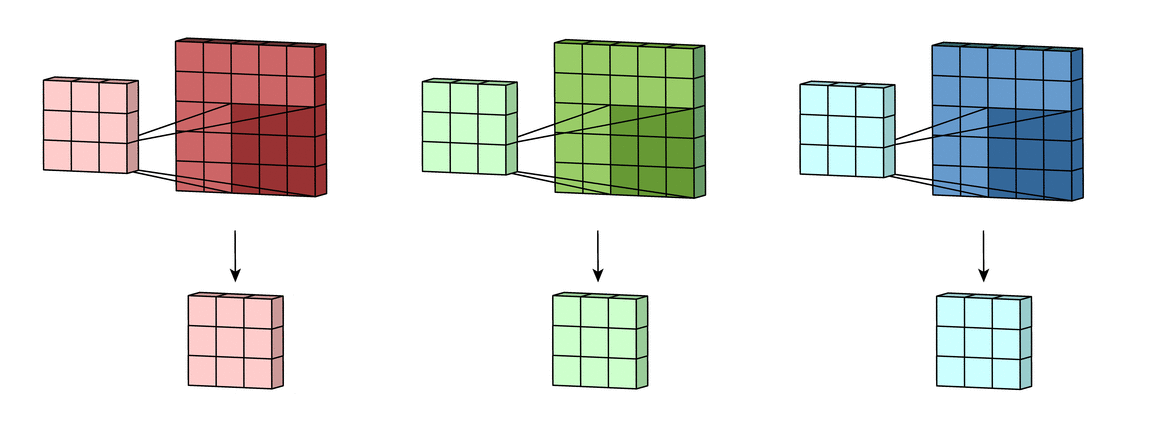
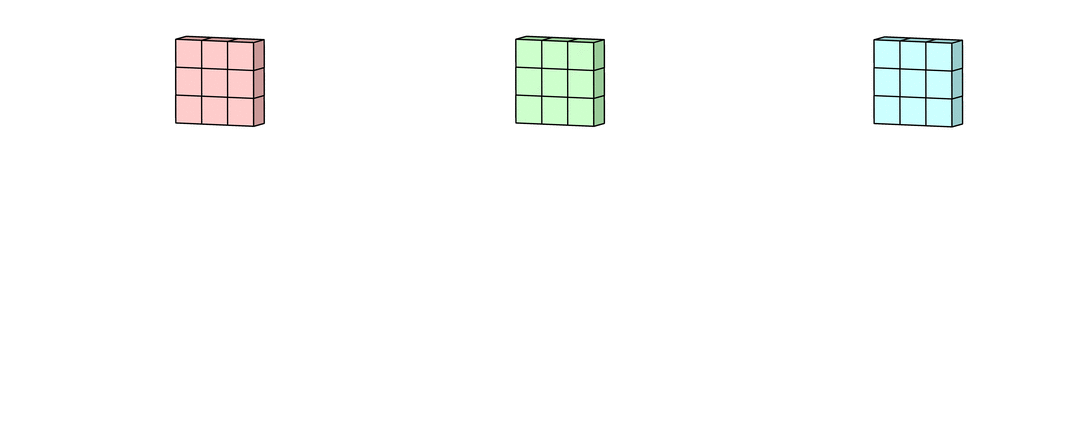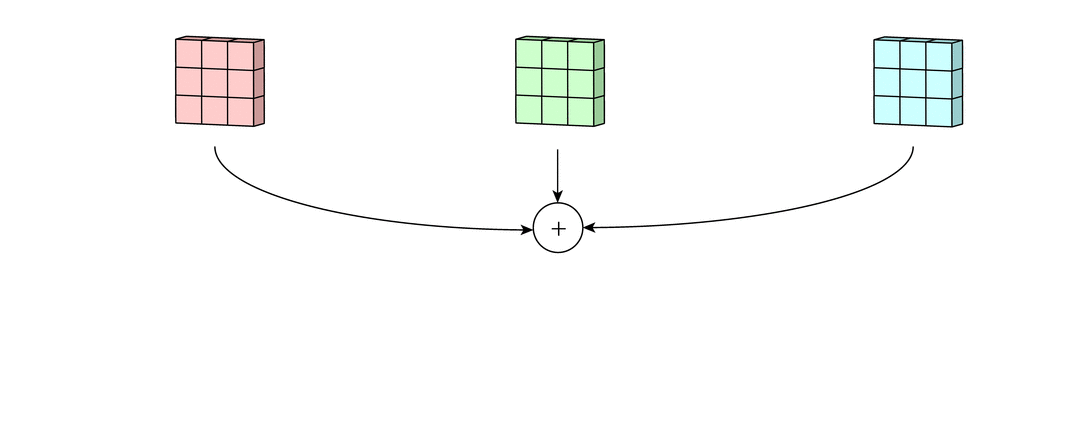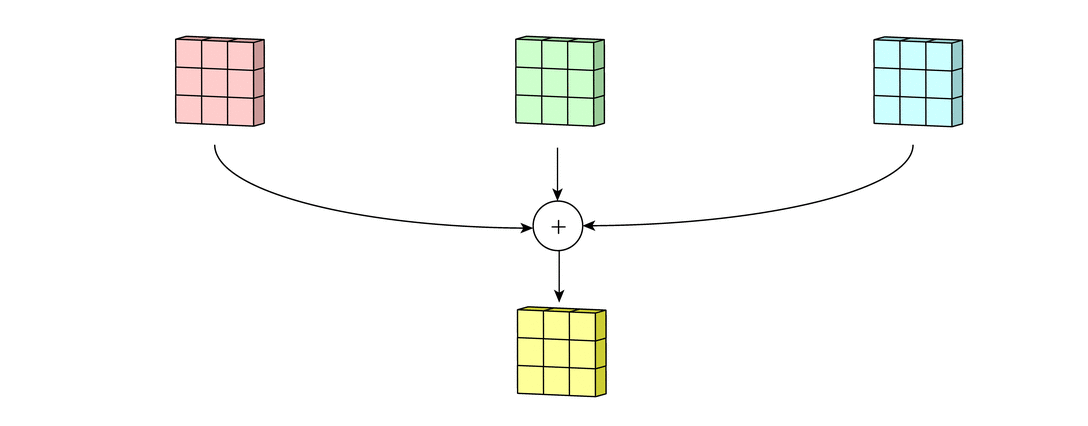
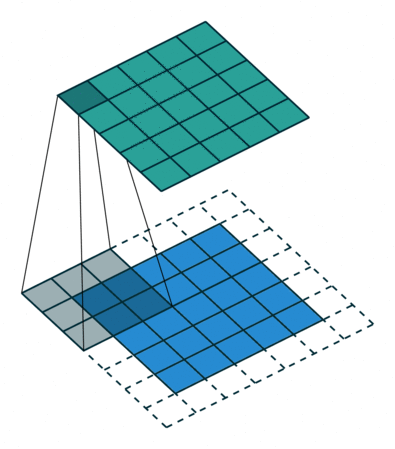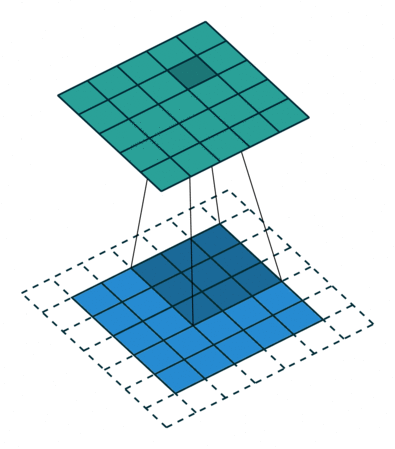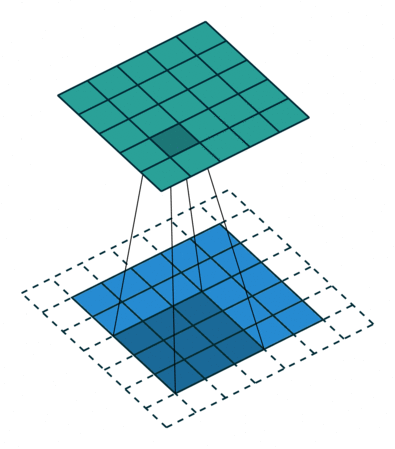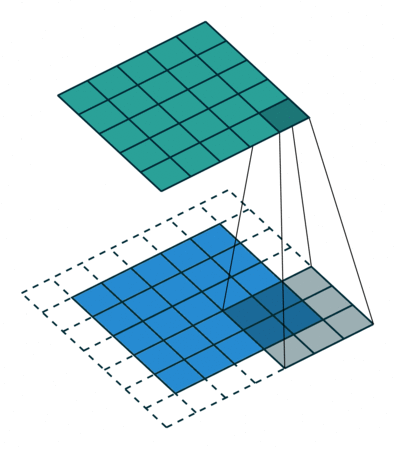
- Convolutional layer is the layer where convolution operation happens. Convolution here is same as on image processing where features are extracted. A filter of same row and column or square size is taken and multiplied across the window that fits filter. The element-wise product is done and summed all. We generally use stride, as how much pixel shift after doing one convolution. Also zero padding is done sometime to add zeros. The convolution layer gives number of filters with same properties. Here more the number of filter, more the accurate model can get but computational complexity increases.
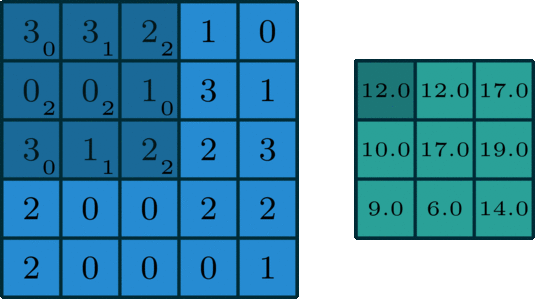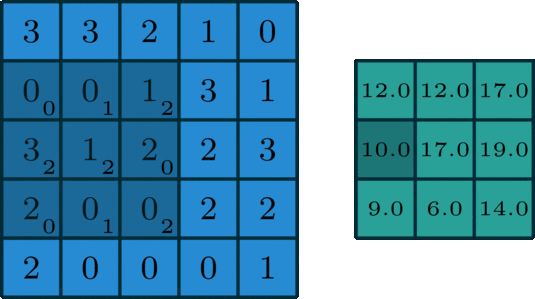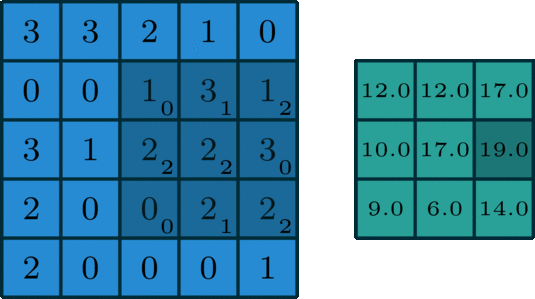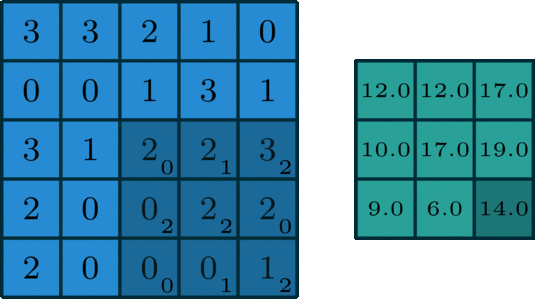
Each CNN layer manipulates image using kernels ex.
What actually happens inside CNN layer?
Inside Grayscale image
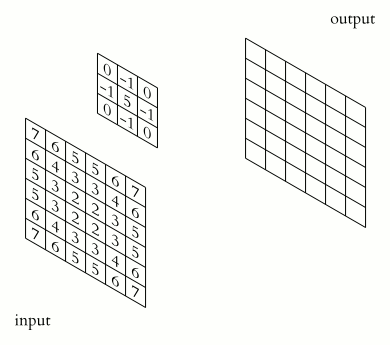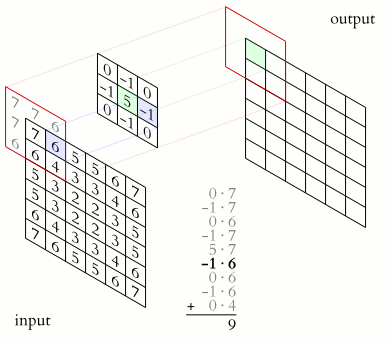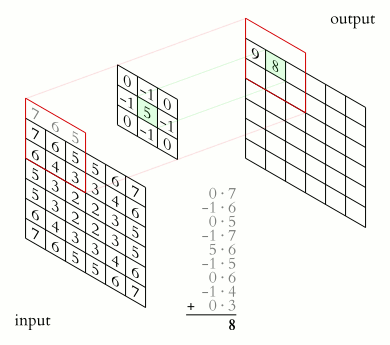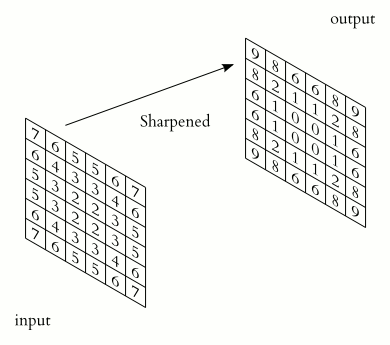
- Max-Pooling layer is a layer where we take only few pixels from previous layers. We must provide a pool size and then that pool size is used on input pixels. The pool window is moved over entire input and max value within the overlaped input is taken. For example, pool of size (2, 2) give half of input data.
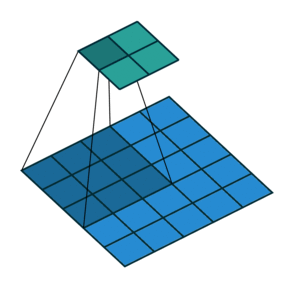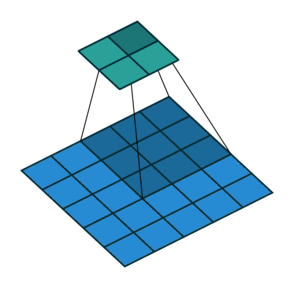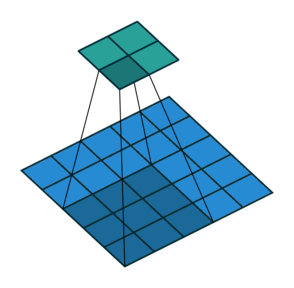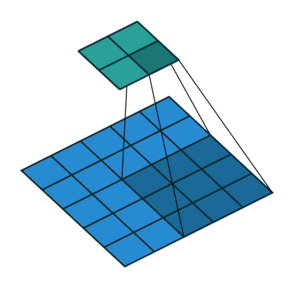
- Dropout is a layer which is actually used to avoid overfitting. This layer randomly cuts the connection between two neurons of different layers. For example, dropout of value 0.5 will cut the half of input's connection. Due to this effect, a NN couldn't memorize input sequence.
- Flatten layer is one where multiple sized input is converted into 1d vector
- Dense layer on CNN this is mostly used to do classification after doing whole convolution thing.
What do we need?
- Keras this is main library we need to import.
- Sequential we use to create model and add layers.
- Layers we mainly use convolution, maxpool, dense layer and dropout layer.
- Optimizers we use various optimizers like SGD, Adam, Adagrad etc.
Sequential method will use create a simplest model of NN.
import keras
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
from keras.optimizers import SGD
import numpy as np
import matplotlib.pyplot as plt
import time
Do you know?
When a machine learning model has high training accuracy and very low validation then this case is known as over-fitting. The reasons for this can be as follows:
- The hypothesis function you are using is too complex that your model perfectly fits the training data but fails to do on test/validation data.
- The number of learning parameters in your model is way too big that instead of generalizing the examples , your model learns those examples and hence the model performs badly on test/validation data.
To solve the above problems a number of solutions can be tried depending on your dataset:
- Use a simple cost and loss function.
- Use regulation which helps in reducing over-fitting i.e Dropout.
- Reduce the number of learning parameters in your model.
These are the 3 solutions that are most likely to improve the validation accuracy of your model and still if these don't work check your inputs whether they have right normalization or not.