EDA: Introduction
Hello everyone, welcome back to another new blog where we will explore different ideas and concept one could perform while performing an EDA. In simple words, this blog is a simple walk-through of an average EDA process which might include (in top down order):
- Data Loading: From various sources (remote, local) and various formats (excel, csv, sql etc).
- Data Check: This is very important task in EDA where we check the data types (numerical, categorical, binary etc) of a data. We often focus on number of missing values.
- Data Transformation: This step in EDA includes filling up null values, or removing them from the table. We also do some data type conversions if required.
- Descriptive Analysis: This is the heart of any EDA because here, we do lots of statistical tasks like finding mean, median, quartile, mode, distribution, relationships of fields. We also plot different plots to support the analysis. This is sometimes enough to give insights about the data and if the data is rich and we need to find more insights and make assumptions, we have to do Inferential Analysis.
- Inferential Analysis: This task sometimes is taken into the EDA part but most of the time we do inferential analysis along with model development. However, we do perform different tests (e.g Chi- Square Test) to calculate feature importance. Here we often do tests based on hypothesis and samples drawn from the population.
While walking through these major steps, one will try to answer different questions of analysis like how many times some categorical data has appeared, what is the distribution over a date, what is the performance over certain cases and so on.
Please follow the following link for the interactive version of this blog General Way of Doing EDA.
Data Loading
Installing Libraries
!pip install autoviz
!pip install seaborn
!pip install plotly
!pip install cufflinks
!pip install pandas- Autoviz is for auto visualization but it is heavy and power hungry. But has many parts of EDA.
- Seaborn is built on top of the matplotlib and is best for making rich static plots. For EDA plots.
- Plotly is for interactive visualization.
- Cufflinks is for connecting pandas and plotly.
- Pandas is for data analysis.
Importing Libraries
If you do not have these libraries installed, please install them like below:
import autoviz
from autoviz.AutoViz_Class import AutoViz_Class
from pandas_profiling import ProfileReport
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import warnings
from plotly.offline import init_notebook_mode, iplot
import plotly.figure_factory as ff
import cufflinks
import plotly.io as pio
cufflinks.go_offline()
cufflinks.set_config_file(world_readable=True, theme='pearl')
pio.renderers.default = "notebook" # should change by looking into pio.renderers
pd.options.display.max_columns = None
%matplotlib inlineIn above step, we have told cufflinks to make plotly plots available offline. And if we are working locally on Jupyter Notebook we should make sure have pio.renderers.default="notebook".
Reading File
To make things easier, I am reading file from local storage which is downloaded from Kaggle.
According to the author, the data is collected by 3 IoT devices under different environmental conditions. These environmental conditions plays major role on the analysis later on.
| device | environmental conditions |
|---|---|
| 00:0f:00:70:91:0a | stable conditions, cooler and more humid |
| 1c:bf:ce:15:ec:4d | highly variable temperature and humidity |
| b8:27:eb:bf:9d:51 | stable conditions, warmer and dryer |
df=pd.read_csv("iot_telemetry_data.csv")Viewing Shape of Data
How many rows and columns are there?
df.shape(405184, 9)There are only 9 columns but lots of rows.
Viewing Top Data
df.head()| ts | device | co | humidity | light | lpg | motion | smoke | temp | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.594512e+09 | b8:27:eb:bf:9d:51 | 0.004956 | 51.000000 | False | 0.007651 | False | 0.020411 | 22.700000 |
| 1 | 1.594512e+09 | 00:0f:00:70:91:0a | 0.002840 | 76.000000 | False | 0.005114 | False | 0.013275 | 19.700001 |
| 2 | 1.594512e+09 | b8:27:eb:bf:9d:51 | 0.004976 | 50.900000 | False | 0.007673 | False | 0.020475 | 22.600000 |
| 3 | 1.594512e+09 | 1c:bf:ce:15:ec:4d | 0.004403 | 76.800003 | True | 0.007023 | False | 0.018628 | 27.000000 |
| 4 | 1.594512e+09 | b8:27:eb:bf:9d:51 | 0.004967 | 50.900000 | False | 0.007664 | False | 0.020448 | 22.600000 |
Data Check
Viewing Data Types
df.dtypests float64
device object
co float64
humidity float64
light bool
lpg float64
motion bool
smoke float64
temp float64
dtype: objectIt seems that we have float data in most of the columns. According to the Author the definition of the columns is
| column | description | units |
|---|---|---|
| ts | timestamp of event | epoch |
| device | unique device name | string |
| co | carbon monoxide | ppm (%) |
| humidity | humidity | percentage |
| light | light detected? | boolean |
| lpg | liquid petroleum gas | ppm (%) |
| motion | motion detected? | boolean |
| smoke | smoke | ppm (%) |
| temp | temperature | Fahrenheit |
Checking Missing Values
This is very crucial as missing values could lead to false assumption and sometimes we have to remove or replace them. Lets check how many of columns have missing values.
total = df.isnull().sum().sort_values(ascending = False)
percent = (df.isnull().sum()/df.isnull().count()).sort_values(ascending = False)
mdf = pd.concat([total, percent], axis=1, keys=['Total', 'Percent'])
mdf = mdf.reset_index()
mdfNumExpr defaulting to 8 threads.| index | Total | Percent | |
|---|---|---|---|
| 0 | ts | 0 | 0.0 |
| 1 | device | 0 | 0.0 |
| 2 | co | 0 | 0.0 |
| 3 | humidity | 0 | 0.0 |
| 4 | light | 0 | 0.0 |
| 5 | lpg | 0 | 0.0 |
| 6 | motion | 0 | 0.0 |
| 7 | smoke | 0 | 0.0 |
| 8 | temp | 0 | 0.0 |
It seems that there is no missing data in our dataset. Which is great. But what about outliers? Because outliers also plays huge role in making data modeling tough task. This task falls under the Descriptive Analysis part.
Data Transformation
It seems that we do not have missing data so we do not have to do much to do besides converting time stamp to datetime.But we might need to transform our data based on the outliers later.
Datetime
Lets convert timestamp to date time because we will visualize some sort of time series analysis later on.
from datetime import datetime
df["date"]= df.ts.apply(datetime.fromtimestamp)Device Name
Lets make our device little bit readable. Create a new column device_name and add the mapped value of environment and device id.
d={"00:0f:00:70:91:0a":"cooler,more,humid",
"1c:bf:ce:15:ec:4d":"variable temp/humidity",
"b8:27:eb:bf:9d:51":"stable, warmer, dry"}
df["device_name"] = df.device.apply(lambda x: d[x])
df| ts | device | co | humidity | light | lpg | motion | smoke | temp | date | device_name | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.594512e+09 | b8:27:eb:bf:9d:51 | 0.004956 | 51.000000 | False | 0.007651 | False | 0.020411 | 22.700000 | 2020-07-12 05:46:34.385975 | stable, warmer, dry |
| 1 | 1.594512e+09 | 00:0f:00:70:91:0a | 0.002840 | 76.000000 | False | 0.005114 | False | 0.013275 | 19.700001 | 2020-07-12 05:46:34.735568 | cooler,more,humid |
| 2 | 1.594512e+09 | b8:27:eb:bf:9d:51 | 0.004976 | 50.900000 | False | 0.007673 | False | 0.020475 | 22.600000 | 2020-07-12 05:46:38.073573 | stable, warmer, dry |
| 3 | 1.594512e+09 | 1c:bf:ce:15:ec:4d | 0.004403 | 76.800003 | True | 0.007023 | False | 0.018628 | 27.000000 | 2020-07-12 05:46:39.589146 | variable temp/humidity |
| 4 | 1.594512e+09 | b8:27:eb:bf:9d:51 | 0.004967 | 50.900000 | False | 0.007664 | False | 0.020448 | 22.600000 | 2020-07-12 05:46:41.761235 | stable, warmer, dry |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 405179 | 1.595203e+09 | 00:0f:00:70:91:0a | 0.003745 | 75.300003 | False | 0.006247 | False | 0.016437 | 19.200001 | 2020-07-20 05:48:33.162015 | cooler,more,humid |
| 405180 | 1.595203e+09 | b8:27:eb:bf:9d:51 | 0.005882 | 48.500000 | False | 0.008660 | False | 0.023301 | 22.200000 | 2020-07-20 05:48:33.576561 | stable, warmer, dry |
| 405181 | 1.595203e+09 | 1c:bf:ce:15:ec:4d | 0.004540 | 75.699997 | True | 0.007181 | False | 0.019076 | 26.600000 | 2020-07-20 05:48:36.167959 | variable temp/humidity |
| 405182 | 1.595203e+09 | 00:0f:00:70:91:0a | 0.003745 | 75.300003 | False | 0.006247 | False | 0.016437 | 19.200001 | 2020-07-20 05:48:36.979522 | cooler,more,humid |
| 405183 | 1.595203e+09 | b8:27:eb:bf:9d:51 | 0.005914 | 48.400000 | False | 0.008695 | False | 0.023400 | 22.200000 | 2020-07-20 05:48:37.264313 | stable, warmer, dry |
Descriptive Analysis
Descriptive Statistics is all about describing the data in the terms of some numbers, charts, graphs or plots. In descriptive statistics, our focus will be on the summary of the data like mean, spread, quartiles, percentiles and so on.
Lets get little bit deep into the descriptive analysis here, we will measure:
- Central tendency which focuses on the average.
- Variability (measure of dispersion) which focuses on how far the data has spreaded.
- Distribution (Frequency distribution) which focuses of number of times something occured.
Frequency Distribution
What is number of observations for each device?
df.groupby("device_name").ts.count().rename("Counts").reset_index().iplot(kind="pie", labels="device_name", values="Counts")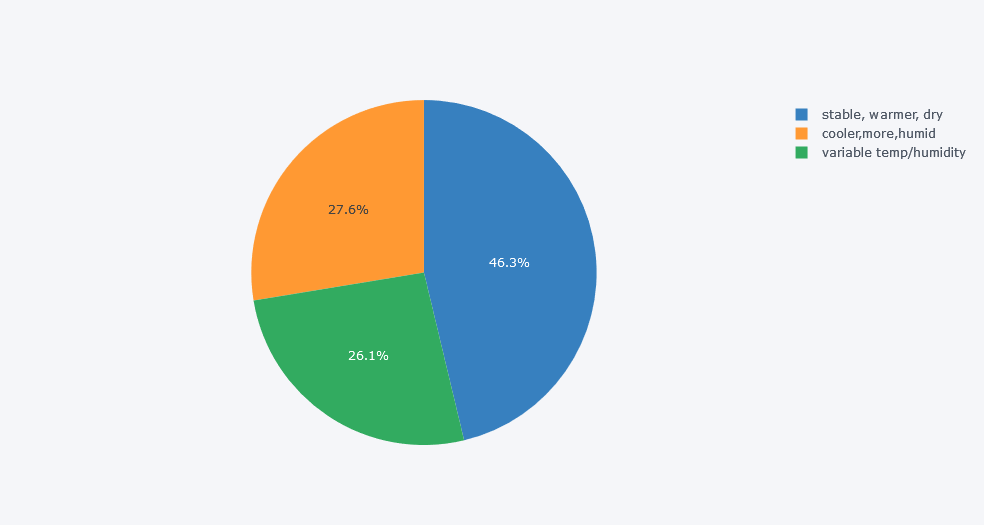
Insights
There seems to be high number of records from the device which was kept on stable, warmer and dry place.
What is the distribution of a field over a time?
This question can be done on the time series analysis but we are not focusing on that in this blog.
We have a date time column prepared already from a timestamp. Lets use that column here.
cols = [i for i in df.columns if i not in ["date", "ts", "device", "device_name"]]
for c in cols:
plt.figure(figsize=(15, 10))
sns.scatterplot(data=df, x="date", y=c, hue="device_name")
plt.title(label=f"Distribution of {c} over a time for each Device")
plt.show()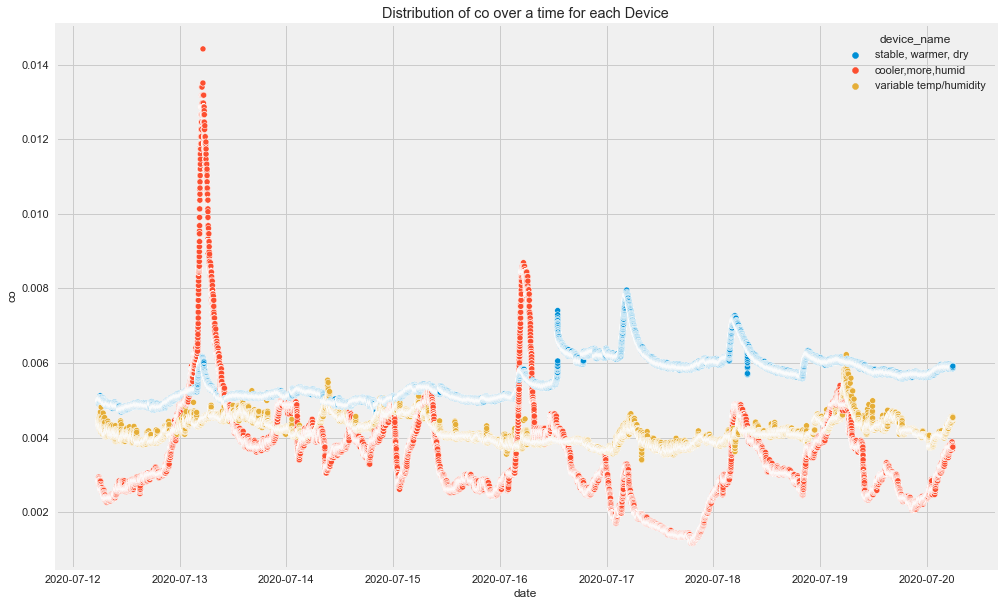
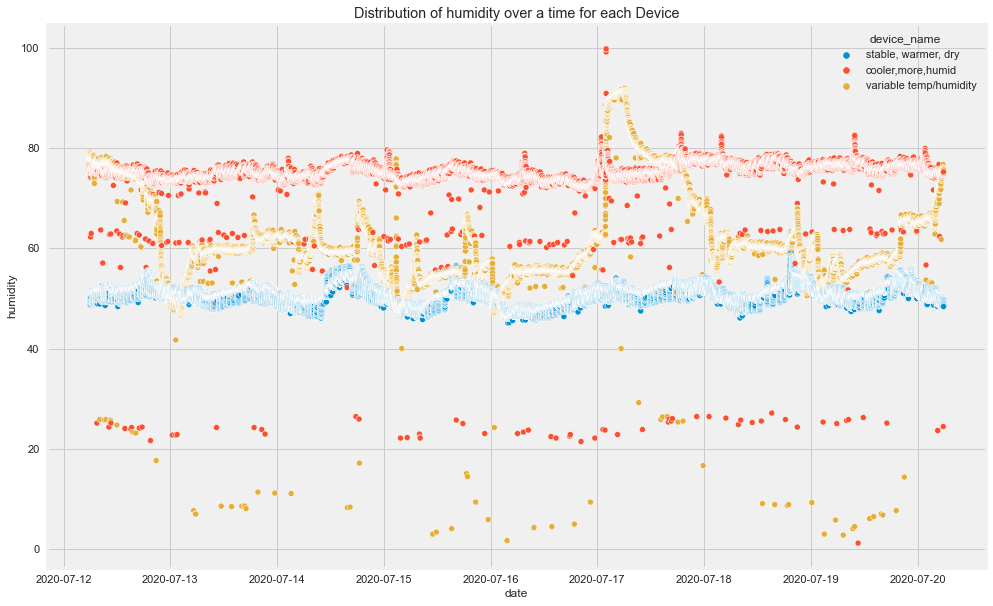
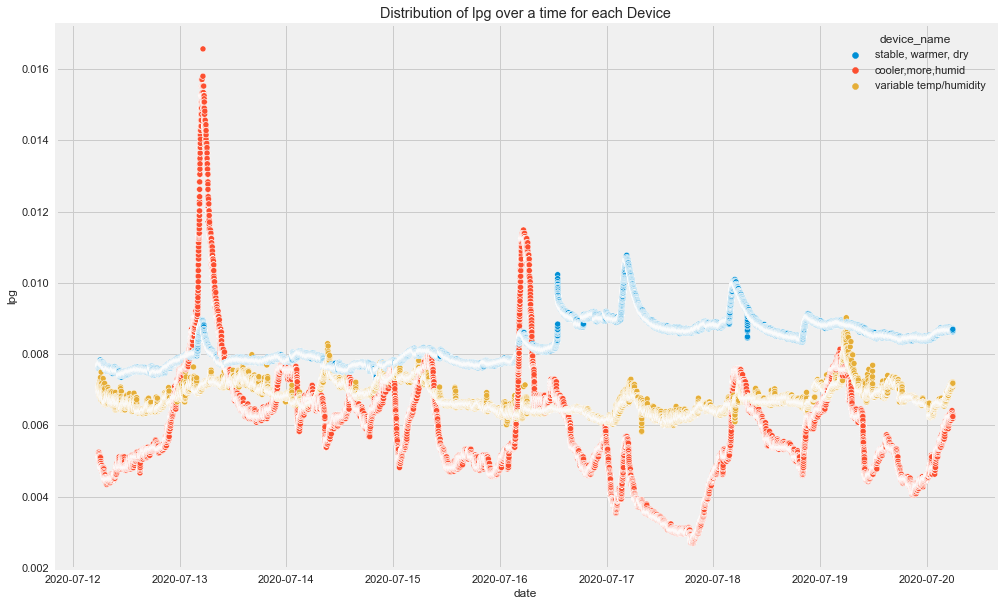
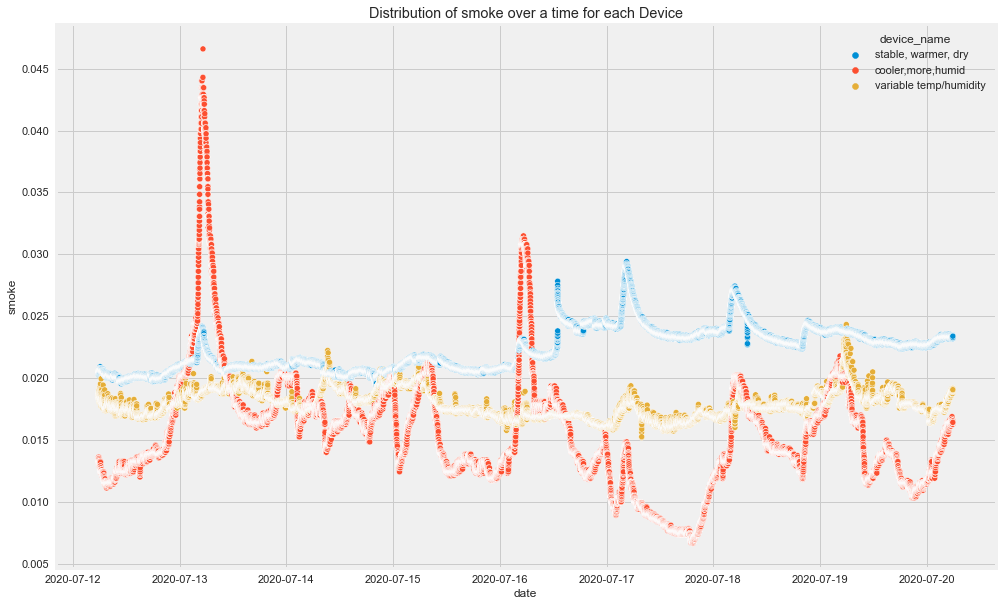
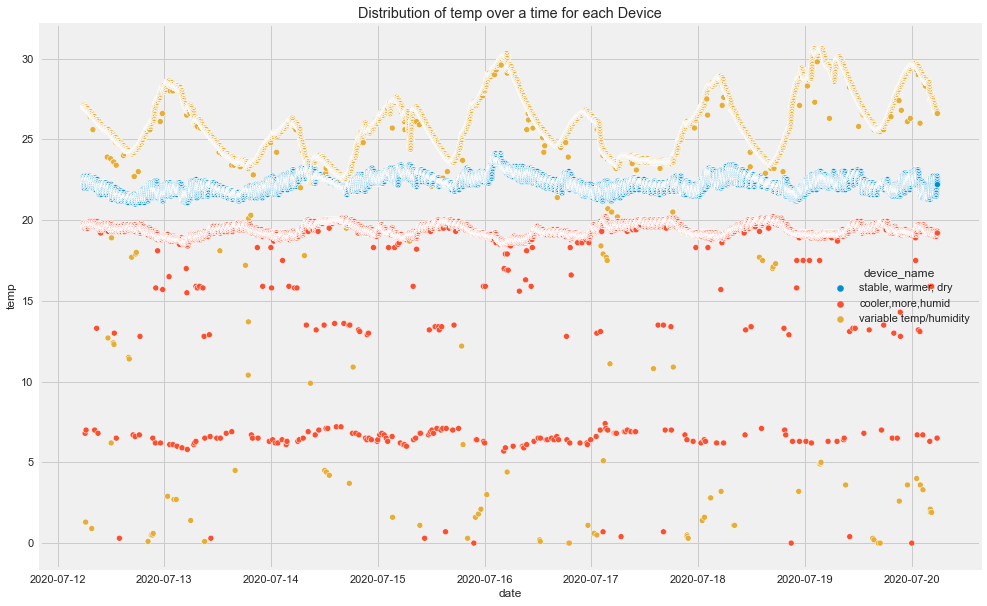
Insights
- There seems to be high spikes in CO recorded by cooler,more humid place's device.
- Humidity seems to be normal for all 3 devices but there is not normal flow for device of cooler, more humid place.
- And LPG seems to decreasing for cooler, more humid and increasing for stable, warmer dry place's device.
- And so on.
What is the distribution of each Columns?
df.co.iplot(kind="hist", xTitle="ppm in %", yTitle="Frequency", title="Frequency Distribution of CO")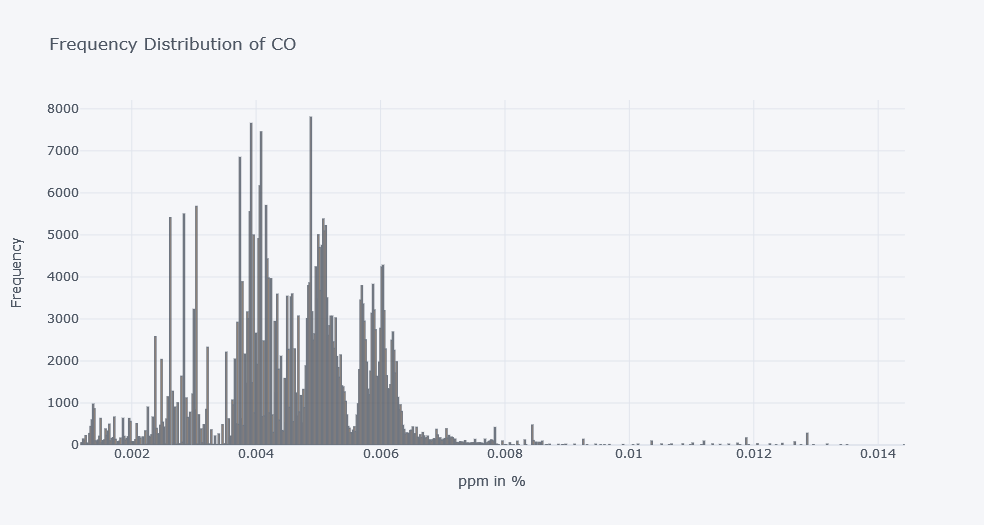
# df.co.plot(kind="hist", title="Frequency Distribution of CO")
plt.figure(figsize=(8,5))
sns.distplot(df.co, kde=False, color='red', bins=100)
plt.title('Frequency Distribution of CO As a Whole', fontsize=18)
plt.xlabel('Units in ppm (%)', fontsize=16)
plt.ylabel('Frequency', fontsize=16)Text(0, 0.5, 'Frequency')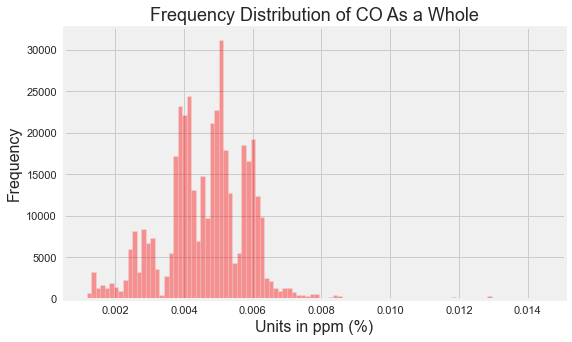
plt.figure(figsize=(18,10))
sns.histplot(data=df, x="co", hue="device_name")
plt.title('Frequency Distribution of CO with Device', fontsize=18)
plt.xlabel('Units in ppm (%)', fontsize=16)
plt.ylabel('Frequency', fontsize=16)Text(0, 0.5, 'Frequency')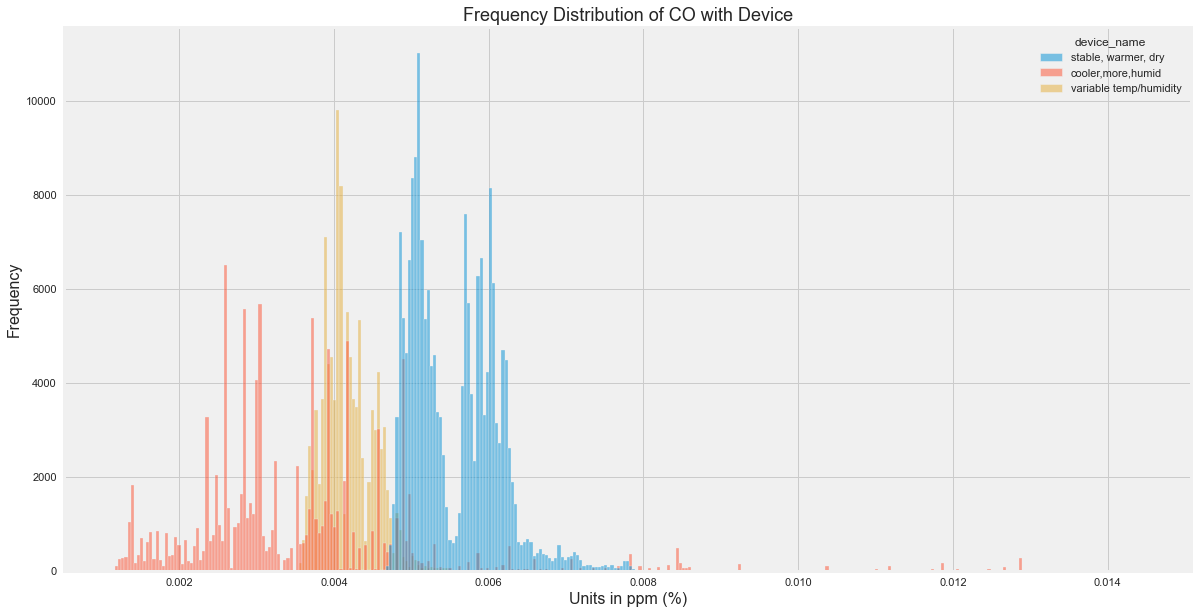
CO Insights\
- It seems that there is huge number of CO readings for ppm 0.004 to 0.006.
- There is some readings of 0.012 too which might be a outliers in our case and we will later visualize it based on the device.
- The device starting with b8 seems to have read much CO. This device was placed on stable conditions, dry places.
All
Lets try to visualize histogram of each fields based on device name.
for c in [i for i in df.columns if i not in ["date", "ts", "device", "device_name"]]:
plt.figure(figsize=(18,10))
sns.histplot(data=df, x=c, hue="device_name")
plt.title(f'Frequency Distribution of {c}', fontsize=18)
plt.xlabel(f'Values of {c}', fontsize=16)
plt.ylabel('Frequency', fontsize=16)
plt.show()
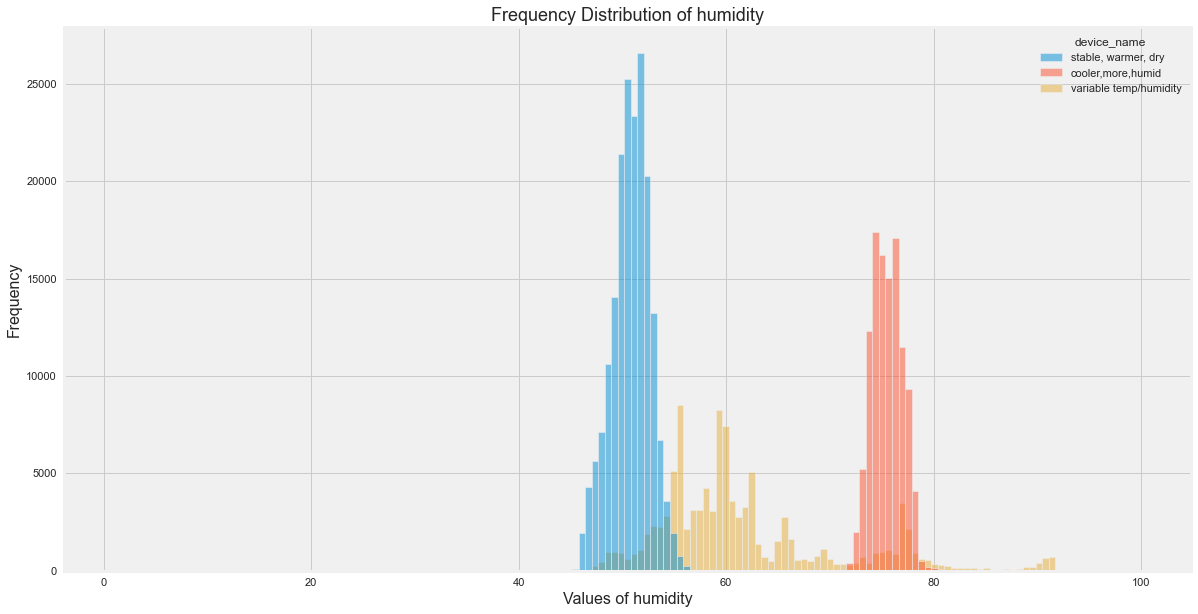
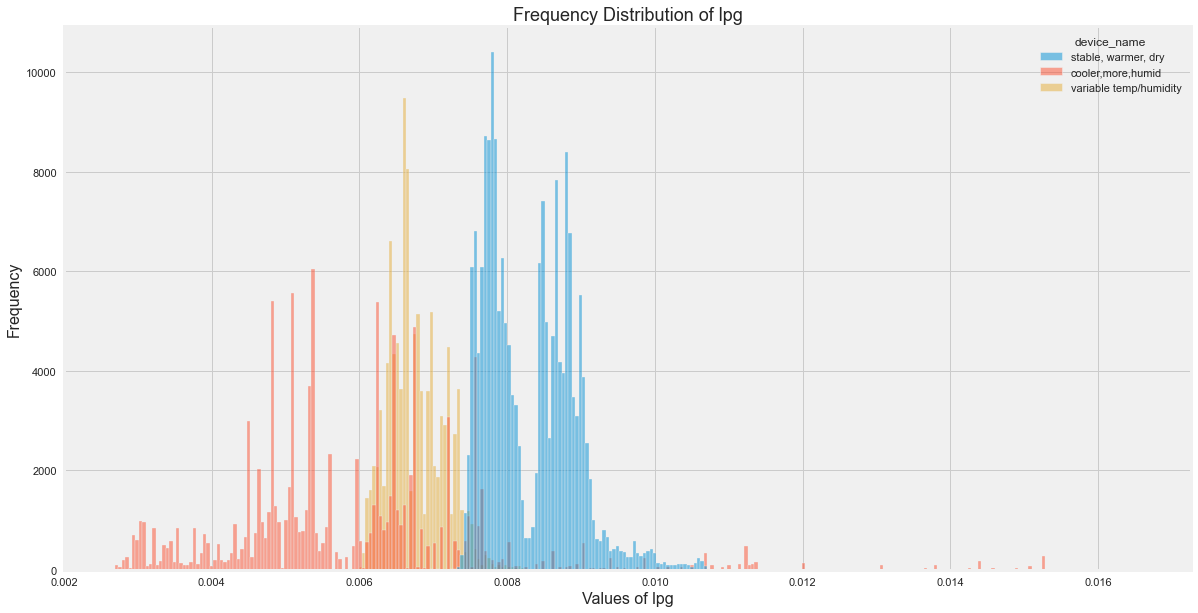
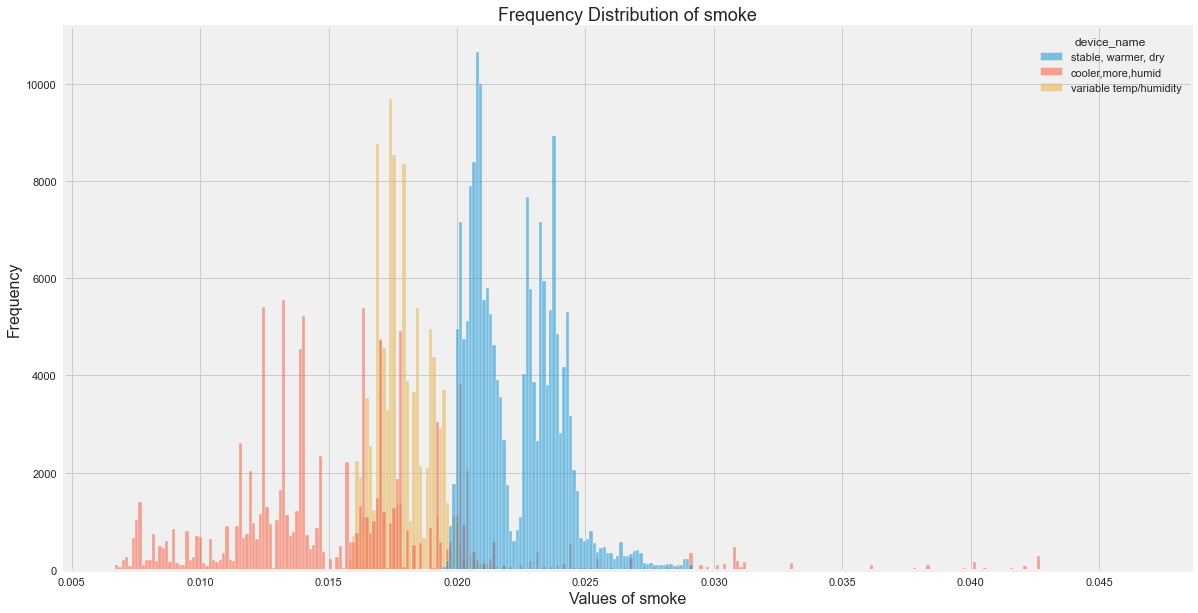
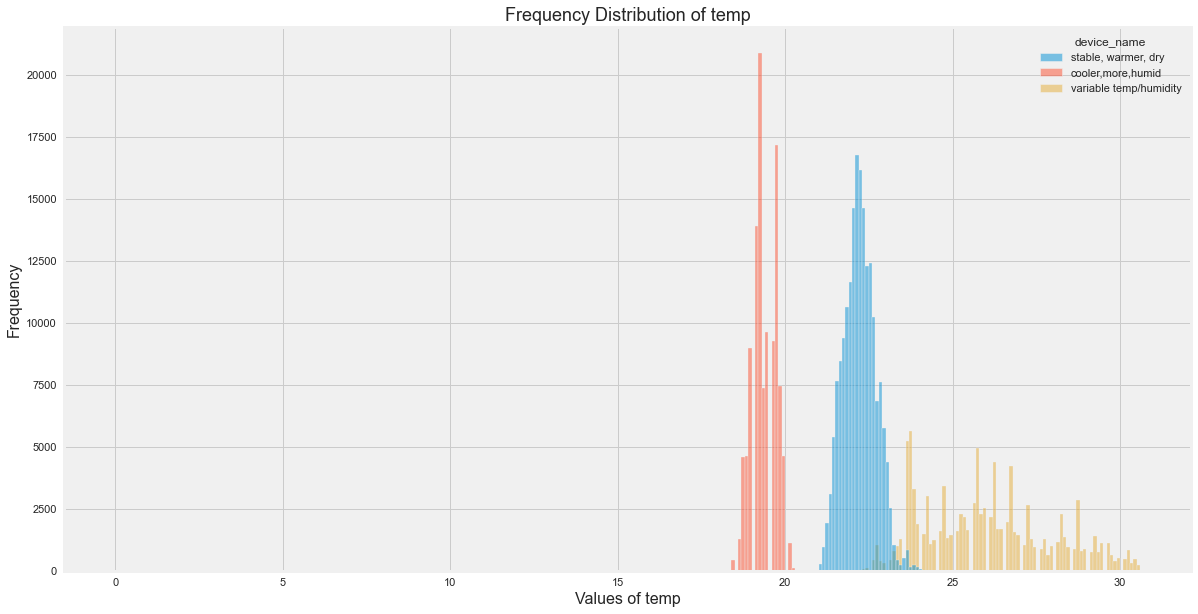
All Insights
- Temp seems to be distributed largely for device which was in variable temp.
- Smoke seems to be distributed largely for device which was in cooler temp.
- LPG seems to be distributed largely for device which was in cooler temp.
Central Tendency
Lets view the summary of each numerical data first.
Overall Insights
df[[i for i in df.columns if i not in ["date", "ts", "device", "device_name"]]].describe()| co | humidity | lpg | smoke | temp | |
|---|---|---|---|---|---|
| count | 405184.000000 | 405184.000000 | 405184.000000 | 405184.000000 | 405184.000000 |
| mean | 0.004639 | 60.511694 | 0.007237 | 0.019264 | 22.453987 |
| std | 0.001250 | 11.366489 | 0.001444 | 0.004086 | 2.698347 |
| min | 0.001171 | 1.100000 | 0.002693 | 0.006692 | 0.000000 |
| 25% | 0.003919 | 51.000000 | 0.006456 | 0.017024 | 19.900000 |
| 50% | 0.004812 | 54.900000 | 0.007489 | 0.019950 | 22.200000 |
| 75% | 0.005409 | 74.300003 | 0.008150 | 0.021838 | 23.600000 |
| max | 0.014420 | 99.900002 | 0.016567 | 0.046590 | 30.600000 |
cols = [i for i in df.columns if i not in ["date", "ts", "device", "device_name", "motion", "light"]]
df[cols].iplot(kind="box", subplots=True)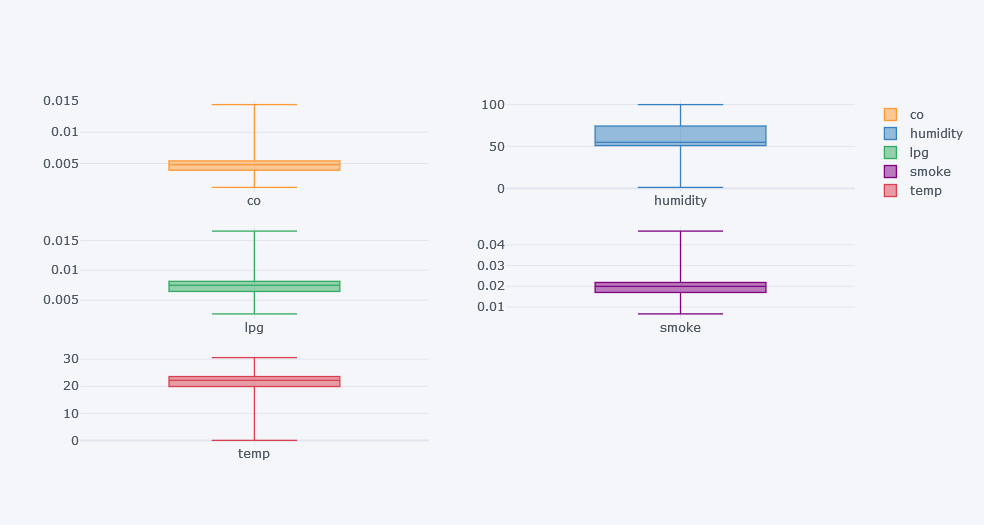
- By hovering over each subplots, we could get the min, max, mean, median values.
- Looking over how the horizontal lines are placed, we could make assumptions like how much is the data skewed.
- It seems there there is high deviation in temperature and humidity which means there could be outliers.
Insights Based on Device
Since our overall data might be biased, we have to look into insights based on device. But why biased? The reasons are:
- Each device was on distinct environment
- Each device have different numbers of recordings
df[[i for i in df.columns if i not in ["date", "ts", "device"]]].groupby("device_name").describe()| co | humidity | lpg | smoke | temp | ||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | mean | std | min | 25% | 50% | 75% | max | count | mean | std | min | 25% | 50% | 75% | max | count | mean | std | min | 25% | 50% | 75% | max | count | mean | std | min | 25% | 50% | 75% | max | count | mean | std | min | 25% | 50% | 75% | max | |
| device_name | ||||||||||||||||||||||||||||||||||||||||
| cooler,more,humid | 111815.0 | 0.003527 | 0.001479 | 0.001171 | 0.002613 | 0.003230 | 0.004116 | 0.014420 | 111815.0 | 75.444361 | 1.975801 | 1.1 | 74.400002 | 75.400002 | 76.500000 | 99.900002 | 111815.0 | 0.005893 | 0.001700 | 0.002693 | 0.004815 | 0.005613 | 0.006689 | 0.016567 | 111815.0 | 0.015489 | 0.004809 | 0.006692 | 0.012445 | 0.014662 | 0.017682 | 0.046590 | 111815.0 | 19.362552 | 0.643786 | 0.0 | 19.100000 | 19.4 | 19.700001 | 20.200001 |
| stable, warmer, dry | 187451.0 | 0.005560 | 0.000559 | 0.004646 | 0.005079 | 0.005439 | 0.005993 | 0.007955 | 187451.0 | 50.814077 | 1.888926 | 45.1 | 49.600000 | 50.900000 | 52.100000 | 63.300000 | 187451.0 | 0.008306 | 0.000599 | 0.007301 | 0.007788 | 0.008183 | 0.008778 | 0.010774 | 187451.0 | 0.022288 | 0.001720 | 0.019416 | 0.020803 | 0.021931 | 0.023640 | 0.029422 | 187451.0 | 22.279969 | 0.481902 | 21.0 | 21.900000 | 22.3 | 22.600000 | 24.100000 |
| variable temp/humidity | 105918.0 | 0.004183 | 0.000320 | 0.003391 | 0.003931 | 0.004089 | 0.004391 | 0.006224 | 105918.0 | 61.910247 | 8.944792 | 1.6 | 55.599998 | 59.599998 | 65.300003 | 92.000000 | 105918.0 | 0.006764 | 0.000373 | 0.005814 | 0.006470 | 0.006657 | 0.007009 | 0.009022 | 105918.0 | 0.017895 | 0.001055 | 0.015224 | 0.017064 | 0.017592 | 0.018589 | 0.024341 | 105918.0 | 26.025511 | 2.026427 | 0.0 | 24.299999 | 25.9 | 27.299999 | 30.600000 |
It is hard to get any insights from above table. Lets view it by looping.
for d in df.device_name.unique():
df.query(f"device_name=='{d}'")[cols].iplot(kind="box", subplots=True, title=f"Box Plot of device placed at {d}")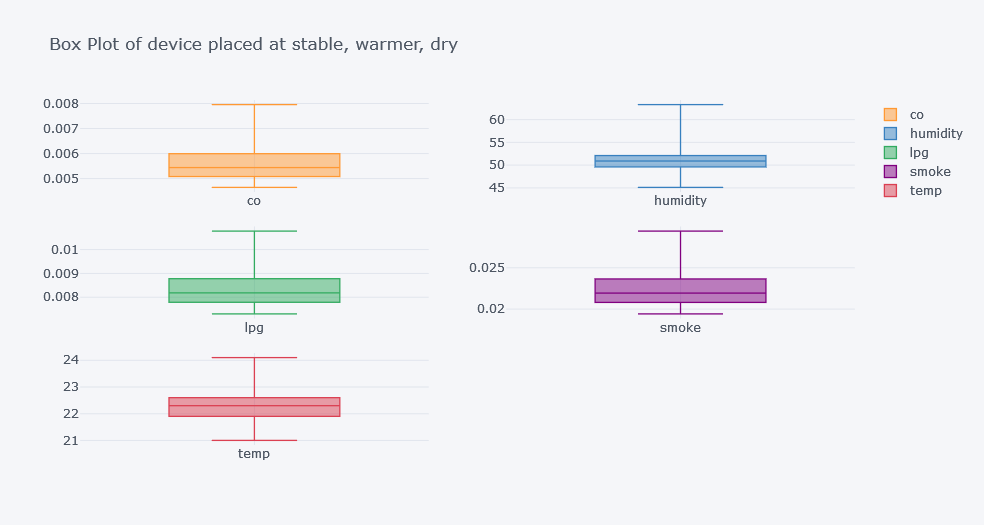
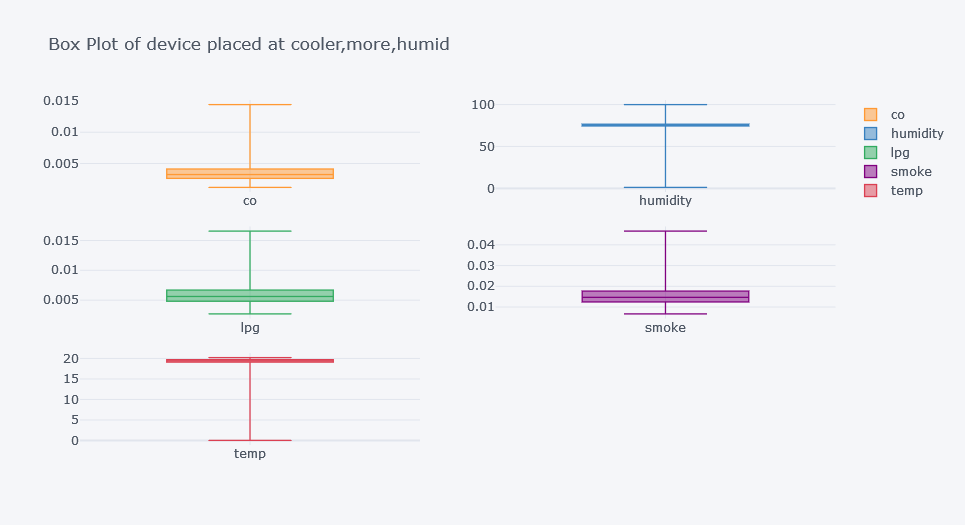
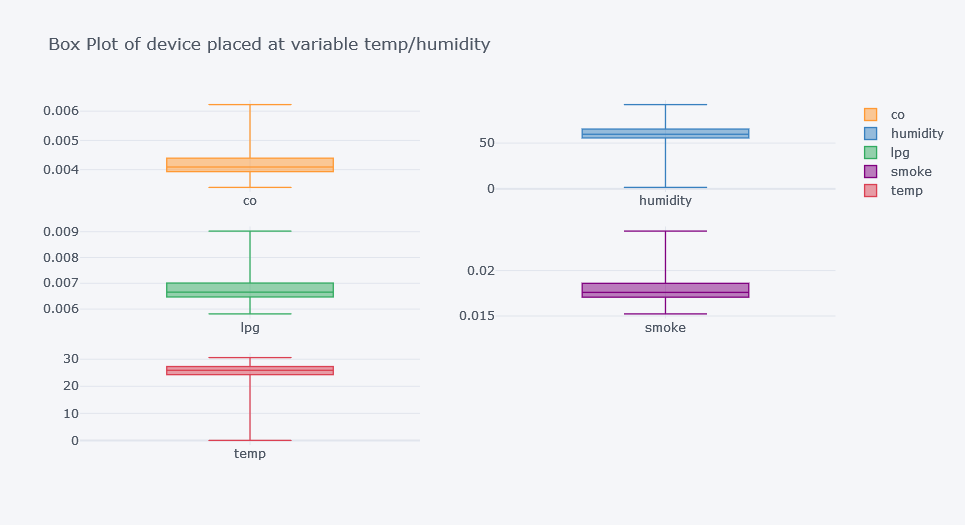
If we observe plots clearly, there can be seen significant difference in each for the column temp.
- CO recorded seems to be higher for a device placed at variable temp. But much spread is of stable, warmer and dry.
- Humidity recorded seems to be lower for stable, warmer dry place's device.
- LPG recorded seems to be well spread on stable, warmer place's device.
- Smoke recorded seems to be spread for stable warmer dry place's device.
- Temperature is self explained that it is lower for cooler place. And so on.
Finding Outliers
for c in cols:
plt.figure(figsize=(15,8))
sns.boxplot(x="device_name", y=c, data=df)
plt.title(label=f"Box Plot of {c}")
plt.show()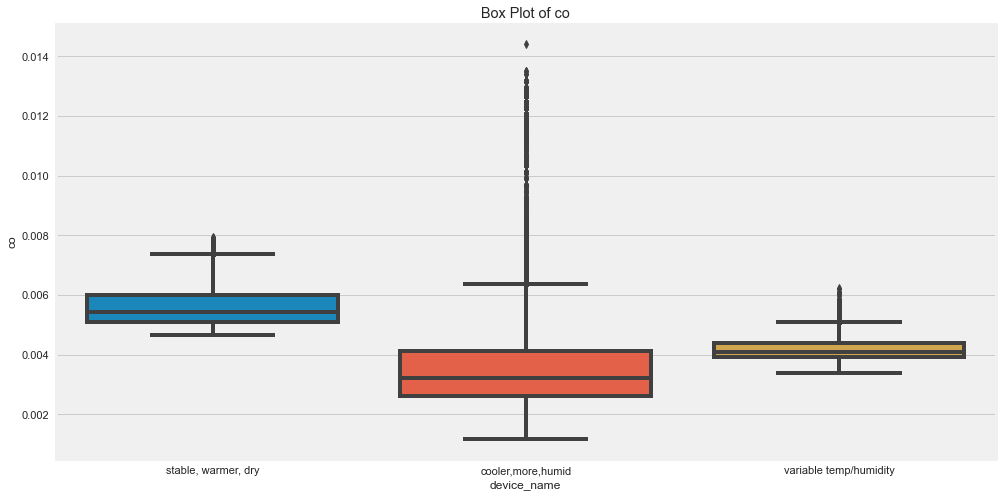
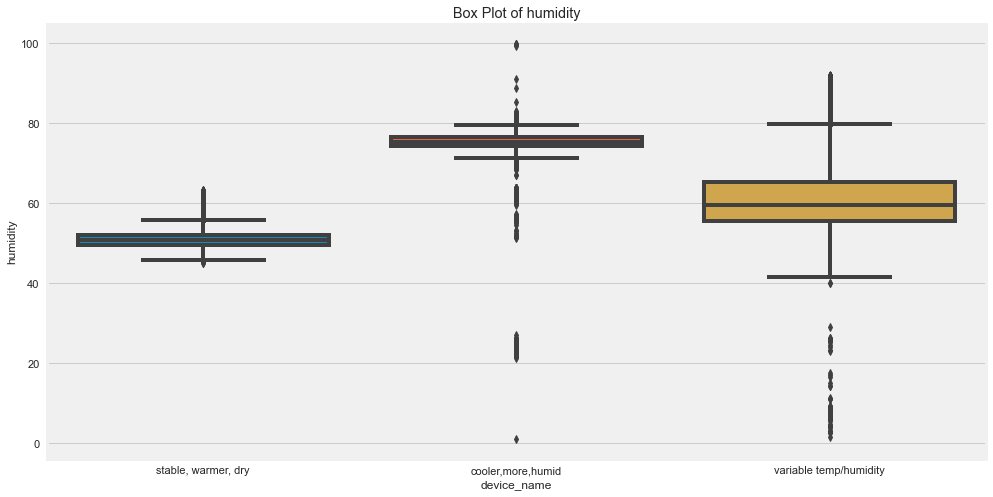
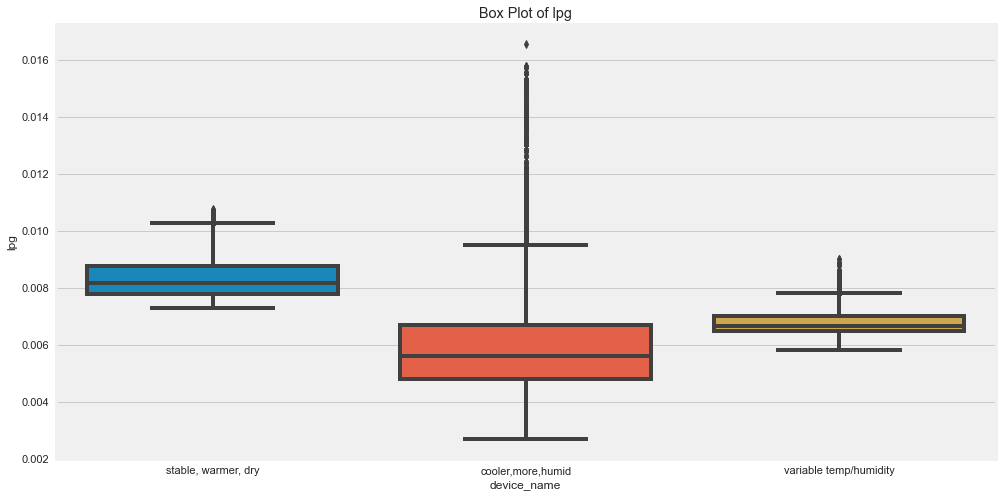
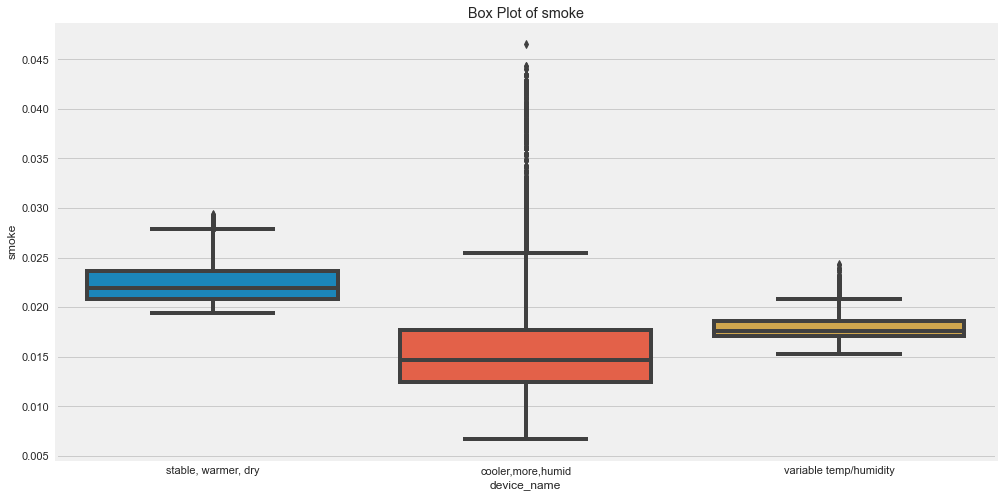
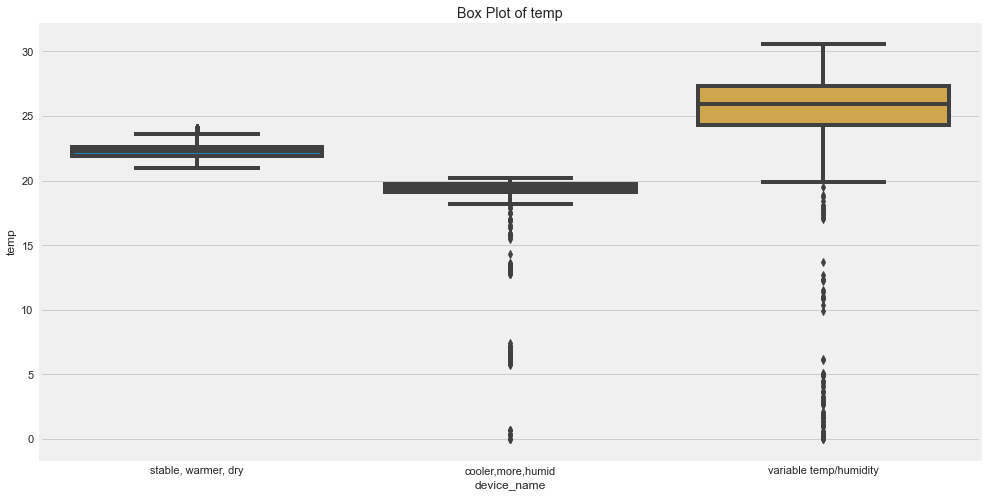
Outliers are those for which points are away from the horizontal bars.
- There seems to be high outliers in co for device which was in cooler, more humid.
- There seems to be high outliers in humidity for device which was in cooler, more humid and variable temp/humidity.
- There seems to be high outliers in LPG for device which was in cooler, more humid.
- There seems to be high outliers in smoke for device which was in cooler, more humid.
- There seems to be high outliers in temp for device which was in cvariable temp/humidity.
Correlations
Lets find Pearson's correlation, whose range lies from -1 to 1. Value of -1 means negatively correlated where as +1 means highly correlated.
Overall
df.corr().iplot(kind="heatmap")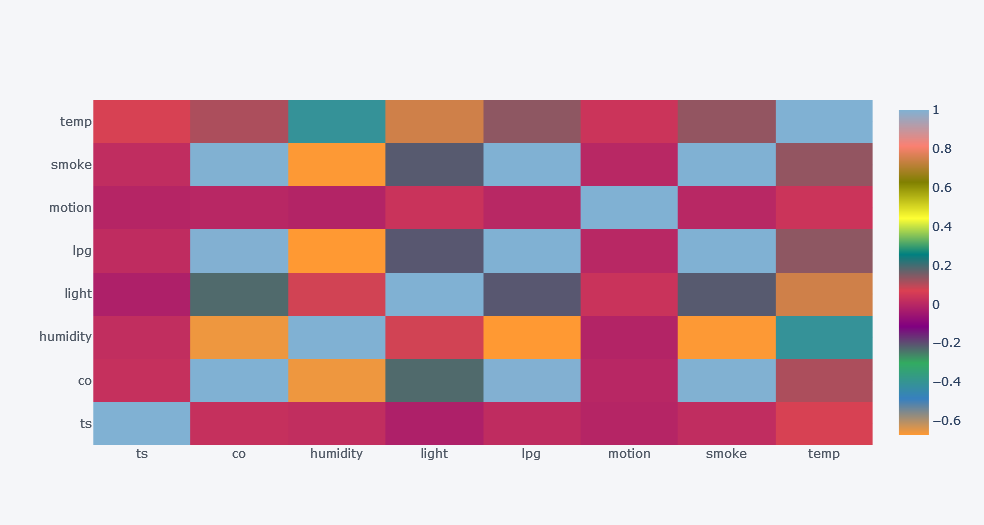
df.corr()| ts | co | humidity | light | lpg | motion | smoke | temp | |
|---|---|---|---|---|---|---|---|---|
| ts | 1.000000 | 0.025757 | 0.017752 | -0.020868 | 0.014178 | -0.006911 | 0.016349 | 0.074443 |
| co | 0.025757 | 1.000000 | -0.656750 | -0.230197 | 0.997331 | -0.000706 | 0.998192 | 0.110905 |
| humidity | 0.017752 | -0.656750 | 1.000000 | 0.079703 | -0.672113 | -0.009826 | -0.669863 | -0.410427 |
| light | -0.020868 | -0.230197 | 0.079703 | 1.000000 | -0.208926 | 0.033594 | -0.212969 | 0.747485 |
| lpg | 0.014178 | 0.997331 | -0.672113 | -0.208926 | 1.000000 | 0.000232 | 0.999916 | 0.136396 |
| motion | -0.006911 | -0.000706 | -0.009826 | 0.033594 | 0.000232 | 1.000000 | 0.000062 | 0.037649 |
| smoke | 0.016349 | 0.998192 | -0.669863 | -0.212969 | 0.999916 | 0.000062 | 1.000000 | 0.131891 |
| temp | 0.074443 | 0.110905 | -0.410427 | 0.747485 | 0.136396 | 0.037649 | 0.131891 | 1.000000 |
- CO have high positive correlation with LPG, Smoke. Negative with Light and Humidity.
- Humidity have negative correlation with smoke, temp, LPG, CO which means that as Humidity increases these fields decreases.
- Light have high correlation with temp.
- Smoke have high correlation with LPG, CO but negative with humidity.
- And so on.
For Each Device
Again, our data is biased and we have to further analyze it for distinct device.
for d in df.device_name.unique():
corr=df.query(f"device_name=='{d}'").corr()
print(corr)
corr.iplot(kind="heatmap", title=f"Correlation of fields for device at {d}") ts co humidity light lpg motion \
ts 1.000000 0.696208 0.042347 -0.112667 0.703218 -0.009851
co 0.696208 1.000000 -0.077022 -0.095929 0.999845 -0.003513
humidity 0.042347 -0.077022 1.000000 -0.042066 -0.079296 -0.007169
light -0.112667 -0.095929 -0.042066 1.000000 -0.096124 0.007202
lpg 0.703218 0.999845 -0.079296 -0.096124 1.000000 -0.003606
motion -0.009851 -0.003513 -0.007169 0.007202 -0.003606 1.000000
smoke 0.701994 0.999895 -0.078891 -0.096093 0.999995 -0.003590
temp 0.149731 -0.035695 -0.372977 0.008124 -0.033369 -0.000086
smoke temp
ts 0.701994 0.149731
co 0.999895 -0.035695
humidity -0.078891 -0.372977
light -0.096093 0.008124
lpg 0.999995 -0.033369
motion -0.003590 -0.000086
smoke 1.000000 -0.033786
temp -0.033786 1.000000 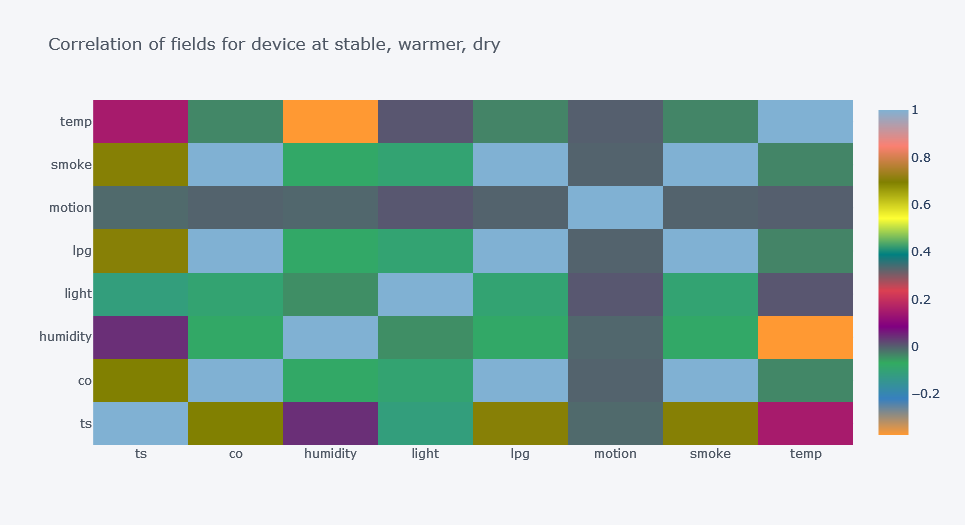
ts co humidity light lpg motion \
ts 1.000000 -0.322829 0.298280 -0.034300 -0.331622 0.004054
co -0.322829 1.000000 -0.221073 -0.048450 0.994789 -0.005022
humidity 0.298280 -0.221073 1.000000 -0.169963 -0.227099 0.022255
light -0.034300 -0.048450 -0.169963 1.000000 -0.047746 0.018596
lpg -0.331622 0.994789 -0.227099 -0.047746 1.000000 -0.005482
motion 0.004054 -0.005022 0.022255 0.018596 -0.005482 1.000000
smoke -0.330315 0.996474 -0.226195 -0.047971 0.999835 -0.005404
temp 0.043851 -0.296603 0.293223 -0.053637 -0.301287 0.001910
smoke temp
ts -0.330315 0.043851
co 0.996474 -0.296603
humidity -0.226195 0.293223
light -0.047971 -0.053637
lpg 0.999835 -0.301287
motion -0.005404 0.001910
smoke 1.000000 -0.300719
temp -0.300719 1.000000 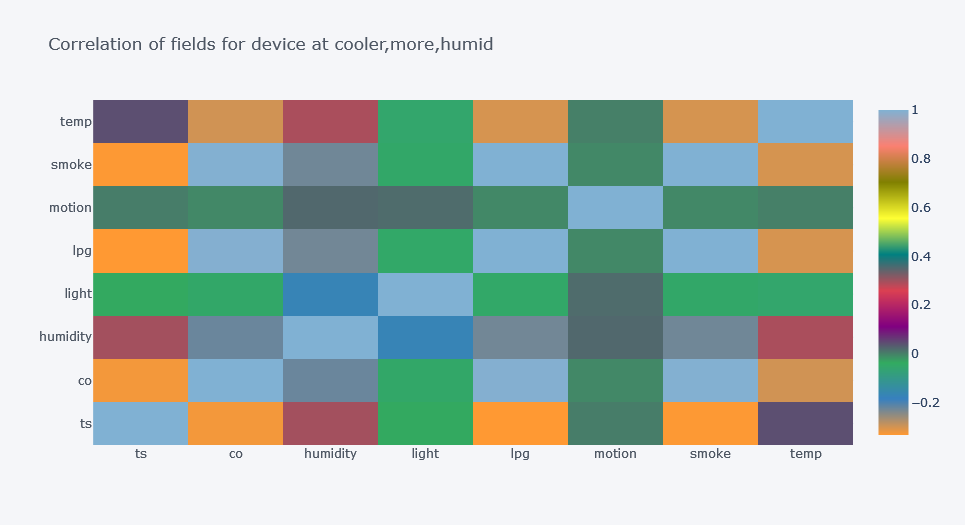
ts co humidity light lpg motion smoke \
ts 1.000000 -0.165952 -0.012370 NaN -0.167243 -0.007758 -0.167018
co -0.165952 1.000000 -0.313322 NaN 0.999907 0.013455 0.999937
humidity -0.012370 -0.313322 1.000000 NaN -0.314211 -0.011879 -0.314058
light NaN NaN NaN NaN NaN NaN NaN
lpg -0.167243 0.999907 -0.314211 NaN 1.000000 0.013532 0.999997
motion -0.007758 0.013455 -0.011879 NaN 0.013532 1.000000 0.013518
smoke -0.167018 0.999937 -0.314058 NaN 0.999997 0.013518 1.000000
temp 0.320340 0.044866 -0.397001 NaN 0.044504 0.021263 0.044566
temp
ts 0.320340
co 0.044866
humidity -0.397001
light NaN
lpg 0.044504
motion 0.021263
smoke 0.044566
temp 1.000000 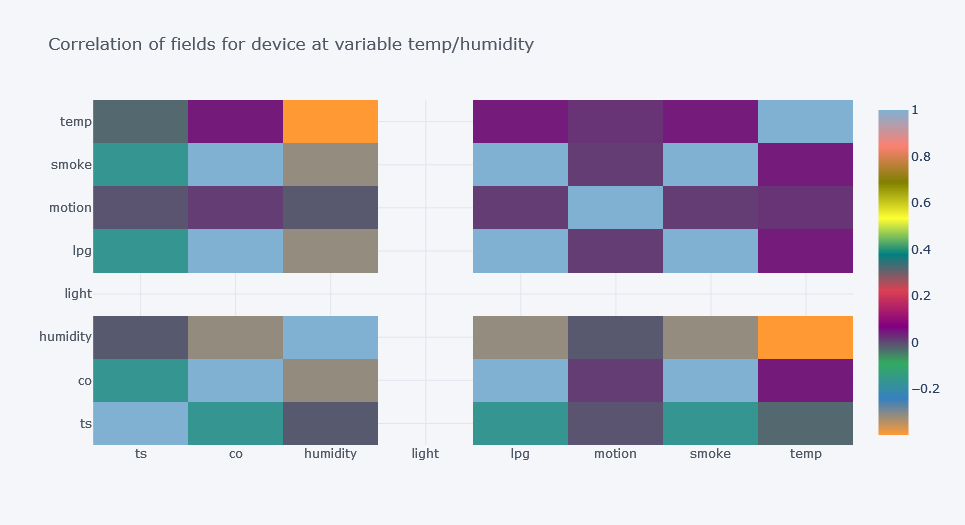
- One valuable insight can be found in first plot where there is high correlation between time and smoke, then co for device at stable and warmer place.
- But there is negative correlation between time and smoke for other two devices.
Conclusion from Descriptive Analysis
As we could see on the above plots and correlation plots, values, we could say that we can not make any judgment based on the overall data because the relationship between fields is different for different place. This could be found in real world that we often have to sub divide the data and perform distinct tests, operations for each. Now we will move on to the next part of our analysis which is Inferential Analysis.
Inferential Data Analysis
In Inferential Statistics, we take a step forward from the descriptive information we had and try to make some inferences or predictions. In general case, we try to prove, estimate and hypothesize something by taking a sample from the population. Mainly in inferential statistics, our focus will be on making conclusion about something.
From our descriptive analysis, we knew that there is difference in correlation values of fields for each device and lets focus our test, hypothesis based on that. There are lots of thing we could inference and test here and I think sky is the limit. Also, looking over the time series analysis, there was distinct grouping of each field for distinct devices.
In all of the inferential analysis there there are mainly two things we do:
- Making inferences or predictions about the population. Example,the average age of the passengers is 29 years.
- Making and testing hypothesis about the populations. Example, whether the survival rate of one gender differs from another’s.
Sampling
Sampling is a concept of taking a small part of a population data with (or without) a hope of having a central tendency of population. Sampling is done when size of the population is high.
Sampling is very popular in risk analyzing. For example, if a bulb company manufactures bulbs then in order to find the durability, they often take small sample and test on it. Similarly, in data collection types like questionnaire, we often make assumptions based on small number of data and try to claim something about a population. If we want to find out what is the ratio of smokers in male/female gender then we will collect small data and perform some tests to claim some conclusion and apply that in the population.
While working with a sample two terms are used to represent sample and population metrics:
- Statistics: It is a measure or metric of sample. e.g. sample average CO.
- Parameter: It is a measure or metric of a population. e.g. population average CO.
Problems with Sampling
- Sample simply means to draw out the subset of the data from the population and whose size should always be smaller than that of the population. One major problem could be found in sampling is that the mean and variance of sample might not ressemble the population. It is often called as sample error.
In Pandas, we could take sample easily. So lets take a sample of size 10k from the population of size 405184.
sample1=df.sample(n=10000)
sd = sample1[cols].describe()
sd| co | humidity | lpg | smoke | temp | |
|---|---|---|---|---|---|
| count | 10000.000000 | 10000.000000 | 10000.000000 | 10000.000000 | 10000.000000 |
| mean | 0.004658 | 60.409360 | 0.007259 | 0.019327 | 22.423650 |
| std | 0.001250 | 11.344686 | 0.001443 | 0.004084 | 2.650209 |
| min | 0.001171 | 4.200000 | 0.002693 | 0.006692 | 5.900000 |
| 25% | 0.003924 | 51.000000 | 0.006462 | 0.017042 | 19.900000 |
| 50% | 0.004828 | 54.600000 | 0.007508 | 0.020004 | 22.200000 |
| 75% | 0.005460 | 74.300003 | 0.008206 | 0.021998 | 23.400000 |
| max | 0.013180 | 91.599998 | 0.015524 | 0.043461 | 30.600000 |
pod = df[cols].describe()
pod| co | humidity | lpg | smoke | temp | |
|---|---|---|---|---|---|
| count | 405184.000000 | 405184.000000 | 405184.000000 | 405184.000000 | 405184.000000 |
| mean | 0.004639 | 60.511694 | 0.007237 | 0.019264 | 22.453987 |
| std | 0.001250 | 11.366489 | 0.001444 | 0.004086 | 2.698347 |
| min | 0.001171 | 1.100000 | 0.002693 | 0.006692 | 0.000000 |
| 25% | 0.003919 | 51.000000 | 0.006456 | 0.017024 | 19.900000 |
| 50% | 0.004812 | 54.900000 | 0.007489 | 0.019950 | 22.200000 |
| 75% | 0.005409 | 74.300003 | 0.008150 | 0.021838 | 23.600000 |
| max | 0.014420 | 99.900002 | 0.016567 | 0.046590 | 30.600000 |
The result will come different each time for the sample because it will have random samples each time. But lets find the difference of sample statistics from population parameters.
pod-sd| co | humidity | lpg | smoke | temp | |
|---|---|---|---|---|---|
| count | 3.951840e+05 | 395184.000000 | 3.951840e+05 | 395184.000000 | 395184.000000 |
| mean | -1.939797e-05 | 0.102334 | -2.223391e-05 | -0.000063 | 0.030337 |
| std | 8.081408e-08 | 0.021803 | 7.320333e-07 | 0.000002 | 0.048138 |
| min | 0.000000e+00 | -3.100000 | 0.000000e+00 | 0.000000 | -5.900000 |
| 25% | -5.239762e-06 | 0.000000 | -6.243145e-06 | -0.000018 | 0.000000 |
| 50% | -1.696835e-05 | 0.300000 | -1.909604e-05 | -0.000054 | 0.000000 |
| 75% | -5.135261e-05 | 0.000000 | -5.590530e-05 | -0.000160 | 0.200000 |
| max | 1.240580e-03 | 8.300003 | 1.043818e-03 | 0.003129 | 0.000000 |
In above table we can see that some value is higher for population while some is for sample.
Estimation
While working with prediction/hypothesis in inferential analysis, we often have to deal with two types of estimates:
- Point Estimation: It is simply a single value estimation for example the sample mean CO is equal to the population mean CO.
- Interval Estimation: This estimation is based on finding a value in some range. For example the confidence interval is used in tests like Chi Square, t-test etc. In above example we have seen that there is difference in the trend of field value for each device. But is it significantly different that we should consider each as distinct?
In above example, we could do point estimation like the Temp mean of sample will be equal to population. Example of interval can be, the population mean of Temp will be around 5% left/right of sample.
Test
Once we are done taking samples and made some estimations, our next step is to test whether we will be able to claim such. So we will test our assumption. This step is known as test.
There are lots of test based upon the nature of estimation, calculation and prediction but all of those can be divided into 3 categories:
- Comparison Test
- Correlation Test
- Regression Test
Based on parameters, we can also categorize tests into two groups:
- Parametric Test: Parametric tests are those in which we work with parameters like mean and variance. One example of this test is t-test.
- Non Parametric Test: These tests are non parametric because does not use parameters in the hypothesis. One example is Mann Whitney U test.
Based on the measurement (Nominal, Ordinal, Interval and Ratio) of the data we can choose best test for our data.
Terms Widely Used in Testing
- Confidence Interval: Confidence interval is all about giving some room for the error. Which is often used with tests. For example, if we are trying to make a test where we have set our hypothesis that the average CO recorded by device first is not more than 2% of device second. Here we are giving some room for possible error.
- Confidence Level: It sounds similar to confidence interval but no it is not. But these two terms are related to each other. Confidence level tells us how much probability is there that the sample statistics or estimated parameter lies within the confidence interval. For example, if we set the confidence level to 5%, then we will be claiming that if there are 100 tests done, at max 5 will be predicting wrong prediction. Or in other words, out of 100 tests, 95 tests will have the estimated value lie within the confidence interval.
- Hypothesis: As the term suggests, hypothesis is something that we are assuming to happen. In Hypothesis testing, we will have different hypothesis against the default or null hypothesis. Those hypothesis against the default are known as alternative hypothesis.
Comparison Test
This kind of test is mostly done where we will compare the parameters, metrics between different samples or population vs sample. Generally we perform parametric tests here.
| Test | Parametric | Comparison With | No. Samples |
|---|---|---|---|
| t-test | Yes | Mean, Variance | 2 |
| ANOVA | Yes | Variance, Mean | 3+ |
| Mann-Whitney U (Wilcoxon Rank Sum) | No | Sum of rankings | 2 |
| Wilcoxon Signed Rank | No | Distributions | 2 |
| Kruskal-Wallis H | No | Mean Rankings | 3+ |
| Mood’s Median | No | Medians | 2+ |
Is the mean value of each fields same for each device's recorded data?
ANOVA means Analysis of Variance. This test is used when we have to compare statistics between two or more samples. If we have two sample, we will use t-test.
Lets test it by assuming 5% of alpha value which is significance level. We assume that if there will be 5 wrong prediction out of 100, then we will ignore it.
- Null Hypothesis: There is no difference in mean values of each devices.
- Alternate Hypothesis: There is significant difference in mean value for each devices.
import statsmodels.api as sm
from statsmodels.formula.api import ols
from statsmodels.stats.anova import anova_lm
# formula = 'len ~ C(supp) + C(dose) + C(supp):C(dose)'
for c in cols:
formula = f'{c} ~ device_name'
model = ols(formula, data=df).fit()
aov_table = anova_lm(model,typ=2)
print(aov_table) sum_sq df F PR(>F)
device_name 0.319266 2.0 206081.057177 0.0
Residual 0.313859 405181.0 NaN NaN
sum_sq df F PR(>F)
device_name 4.276879e+07 2.0 904472.329682 0.0
Residual 9.579674e+06 405181.0 NaN NaN
sum_sq df F PR(>F)
device_name 0.439852 2.0 219945.965812 0.0
Residual 0.405145 405181.0 NaN NaN
sum_sq df F PR(>F)
device_name 3.506427 2.0 217991.815523 0.0
Residual 3.258695 405181.0 NaN NaN
sum_sq df F PR(>F)
device_name 2.425356e+06 2.0 936247.353097 0.0
Residual 5.248123e+05 405181.0 NaN NaNIt seems that that the p value is smaller than 5%, thus we reject the null hypothesis and claim that there is significant difference in mean values of fields of each device. But lets use ANOVA from SciPy's stats and result must be same.
import scipy.stats as stats
for c in cols:
devs = df.device_name.unique()
groups = df.groupby("device_name").groups
co0 = df[c][groups[devs[0]]]
co1 = df[c][groups[devs[1]]]
co2 = df[c][groups[devs[2]]]
print(stats.f_oneway(co0, co1, co2))F_onewayResult(statistic=206081.05717747274, pvalue=0.0)
F_onewayResult(statistic=904472.329681998, pvalue=0.0)
F_onewayResult(statistic=219945.96581178883, pvalue=0.0)
F_onewayResult(statistic=217991.81552333018, pvalue=0.0)
F_onewayResult(statistic=936247.3530974094, pvalue=0.0)Correlation Test
Correlation tests are done to calculate the strength of the association between data.
| Test | Parametric | Data Type |
|---|---|---|
| Pearson’s r | Yes | Interval/Ratio |
| Spearman’s r | No | Ordinal/Interval/Ratio |
| Chi Square Test of Independence | No | Nominal/Ordinal |
Pearson's r test is statistically powerful than Spearman's but Spearman's test is appropriate for interval and ratio type of data.
Only Chi Square Test of Independence is the only test that can be used with nominal variables.
Pearson's and Spearman's Test
Pearson's Test For Linear Relationship Between Variables
The coefficient returns a value between -1 and 1 that represents the limits of correlation from a full negative correlation to a full positive correlation. A value of 0 means no correlation. The value must be interpreted, where often a value below -0.5 or above 0.5 indicates a notable correlation, and values below those values suggests a less notable correlation.
A formula is:

From Wikipedia
We have already done this test on the Descriptive Analysis Part.
Spearman’s Correlation: Non-Linear Relationship between two variables.
Two variables may be related by a nonlinear relationship, such that the relationship is stronger or weaker across the distribution of the variables. In this case Spearman's correlation is used.
Pearson correlation assumes the data is normally distributed. However, Spearman does not make any assumption on the distribution of the data. That is the main difference between these two.

From Wikipedia
df.corr("spearman")| ts | co | humidity | light | lpg | motion | smoke | temp | |
|---|---|---|---|---|---|---|---|---|
| ts | 1.000000 | 0.077576 | 0.051555 | -0.020867 | 0.077576 | -0.006917 | 0.077576 | 0.055377 |
| co | 0.077576 | 1.000000 | -0.764622 | -0.337479 | 1.000000 | -0.003210 | 1.000000 | 0.121469 |
| humidity | 0.051555 | -0.764622 | 1.000000 | 0.210620 | -0.764622 | -0.006705 | -0.764622 | -0.334038 |
| light | -0.020867 | -0.337479 | 0.210620 | 1.000000 | -0.337479 | 0.033594 | -0.337479 | 0.713951 |
| lpg | 0.077576 | 1.000000 | -0.764622 | -0.337479 | 1.000000 | -0.003210 | 1.000000 | 0.121469 |
| motion | -0.006917 | -0.003210 | -0.006705 | 0.033594 | -0.003210 | 1.000000 | -0.003210 | 0.033095 |
| smoke | 0.077576 | 1.000000 | -0.764622 | -0.337479 | 1.000000 | -0.003210 | 1.000000 | 0.121469 |
| temp | 0.055377 | 0.121469 | -0.334038 | 0.713951 | 0.121469 | 0.033095 | 0.121469 | 1.000000 |
Insights
Some of notable insights:
- High +ve correlation of co with lpg, smoke.
- High -ve correlation of humidity with co, lpg.
- High +ve correlation of light with temp.
- And so on.
Chi Square Test
The Chi-square test is a non-parametric statistic, also called a distribution free test. Non-parametric tests should be used when any one of the following conditions pertains to the data:
- The level of measurement of all the variables is nominal or ordinal.
- The sample sizes of the study groups are unequal; for the χ2 the groups may be of equal size or unequal size whereas some parametric tests require groups of equal or approximately equal size.
- The original data were measured at an interval or ratio level, but violate one of the following assumptions of a parametric test:
- The distribution of the data was seriously skewed or kurtotic (parametric tests assume approximately normal distribution of the dependent variable), and thus the researcher must use a distribution free statistic rather than a parametric statistic.
- The data violate the assumptions of equal variance or homoscedasticity.
- For any of a number of reasons (1), the continuous data were collapsed into a small number of categories, and thus the data are no longer interval or ratio.
Note:
-
Null Hypothesis(H0): Two variables are not dependent. (no association between the two variables)
-
Alternate Hypothesis(H1): There is relationship between variables.
-
If Statistic >= Critical Value: significant result, reject null hypothesis (H0), dependent.
-
If Statistic < Critical Value: not significant result, fail to reject null hypothesis (H0), independent.
In terms of a p-value and a chosen significance level (alpha), the test can be interpreted as follows:
- If p-value <= alpha: significant result, reject null hypothesis (H0), dependent.
- If p-value > alpha: not significant result, fail to reject null hypothesis (H0), independent.
We do not have nominal data here thus we will not perform any test here yet.
Collinearity vs Multicollinearity
Correlation and collinearity are similar things with few differences:
- Correlation measures the relationship strength and direction of the relationship between two fields in our data.
- Collinearity is a situation where two fields are linearly associated (high correlation) and they are used as predictors for the target.
- Multicollinearity is a case if collinearity where a there exists linear relationship with two or more features.
While training ML models, it is important that we remove those features that exhibit multicollinearity and we could do so by calculating VIF (Variance Inflation Factor). VIF allows us to determine the strength of correlation between other variables.
VIF calculates how much the variance of a coefficient is inflated because of its linear dependencies with other predictors. Hence its name.
Referenced from here.
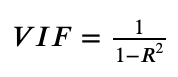
(1-R**2)is known as tolerance factor.
R-squared (R2) is a statistical measure that represents the proportion of the variance for a dependent variable that's explained by an independent variable or variables in a regression model
Referenced from here.
Interpreting VIF:
- 1 — features are not correlated
- 1<VIF<5 — features are moderately correlated
- VIF>5 — features are highly correlated
- VIF>10 — high correlation between features and is cause for concern
from sklearn.linear_model import LinearRegression
def calculate_vif(df, features):
vif, tolerance = {}, {}
# all the features that you want to examine
for feature in features:
# extract all the other features you will regress against
X = [f for f in features if f != feature]
X, y = df[X], df[feature]
# extract r-squared from the fit
r2 = LinearRegression().fit(X, y).score(X, y)
# calculate tolerance
tolerance[feature] = 1 - r2
# calculate VIF
vif[feature] = 1/(tolerance[feature])
# return VIF DataFrame
return pd.DataFrame({'VIF': vif, 'Tolerance': tolerance})Now calculating VIF of our columns with each other.
calculate_vif(df=df, features=[c for c in df.columns if c not in ["device", "device_name", "date"]])| VIF | Tolerance | |
|---|---|---|
| ts | 1.124875e+00 | 8.889881e-01 |
| co | 8.709637e+04 | 1.148153e-05 |
| humidity | 3.618642e+00 | 2.763468e-01 |
| light | 4.123083e+00 | 2.425369e-01 |
| lpg | 1.872582e+06 | 5.340219e-07 |
| motion | 1.001580e+00 | 9.984225e-01 |
| smoke | 2.765493e+06 | 3.615991e-07 |
| temp | 4.835901e+00 | 2.067867e-01 |
In above table, we can see that,
- LPG, Smoke, CO have high correlation between other features and thus it can be our concerned features.
- Also Temp, Humidity seems to be having good correlation but Time stamp, motion, does not seem to be having good relationships.
Lets remove co as highly correlated feature and calculating VIF again to see what effect can be seen.
calculate_vif(df=df, features=[c for c in df.columns if c not in ["device", "device_name", "date", "co"]])| VIF | Tolerance | |
|---|---|---|
| ts | 1.085452 | 0.921275 |
| humidity | 3.079545 | 0.324723 |
| light | 4.023971 | 0.248511 |
| lpg | 7206.123295 | 0.000139 |
| motion | 1.001578 | 0.998424 |
| smoke | 7185.519140 | 0.000139 |
| temp | 4.833069 | 0.206908 |
The change can be seen in the terms that the VIF of LPG, Smoke has also decreased. It is sure that these 3 fields have high collinearity. Now again removing feature smoke and calculating VIF.
calculate_vif(df=df, features=[c for c in df.columns if c not in ["device", "device_name", "date", "smoke"]])| VIF | Tolerance | |
|---|---|---|
| ts | 1.081658 | 0.924507 |
| co | 226.300545 | 0.004419 |
| humidity | 3.096043 | 0.322993 |
| light | 4.017793 | 0.248893 |
| lpg | 231.395623 | 0.004322 |
| motion | 1.001578 | 0.998425 |
| temp | 4.832018 | 0.206953 |
The changes seems to be more reflected. And it is clear that smoke have more collinearity than that of co with others. But again checking by removing LPG and calculating VIF.
calculate_vif(df=df, features=[c for c in df.columns if c not in ["device", "device_name", "date", "lpg"]])| VIF | Tolerance | |
|---|---|---|
| ts | 1.080860 | 0.925189 |
| co | 335.166702 | 0.002984 |
| humidity | 3.101372 | 0.322438 |
| light | 4.016575 | 0.248968 |
| motion | 1.001578 | 0.998425 |
| smoke | 341.732959 | 0.002926 |
| temp | 4.831788 | 0.206963 |
The effects are similar to the case where we removed smoke.
Regression Tests
Regression tests are done where we try to estimate some parameter. If we have one dependent and one independent variable then we will be using simple linear regression like $y=mx+c$. If we have multiple variables then it will be mulilinear regression. But besides linear, there is logistic regression which tries to classify between two class.
The regression test examines whether the change is dependent variable have any effect in the independent variable or not.
| Test | Predictor | Outcome |
|---|---|---|
| Simple Linear | 1 interval/ratio | 1 interval/ratio |
| Multi Linear | 2+ interval/ratio | 1 interval/ratio |
| Logistic regression | 1+ | 1 binary |
| Nominal regression | 1+ | 1 nominal |
| Ordinal regression | 1+ | 1 ordinal |
The linear relationship between features has been already discovered like the rise in CO has something to do with LPG and Smoke thus we can skip this test for now.
Using Autoviz for Fast EDA
Autoviz is a kind of auto EDA tool which performs lots of EDA and plots graphs and provides some valuable insights. However, manual EDA always gives much insights if we have time to perform one. And using Pandas profiler, we can get insights like correlation in terms of sentence.
av = AutoViz_Class()
dfa = av.AutoViz("iot_telemetry_data.csv")
max_rows_analyzed is smaller than dataset shape 405184...
randomly sampled 150000 rows from read CSV file
Shape of your Data Set loaded: (150000, 9)
############## C L A S S I F Y I N G V A R I A B L E S ####################
Classifying variables in data set...
9 Predictors classified...
No variables removed since no ID or low-information variables found in data set
Since Number of Rows in data 150000 exceeds maximum, randomly sampling 150000 rows for EDA...
Number of All Scatter Plots = 21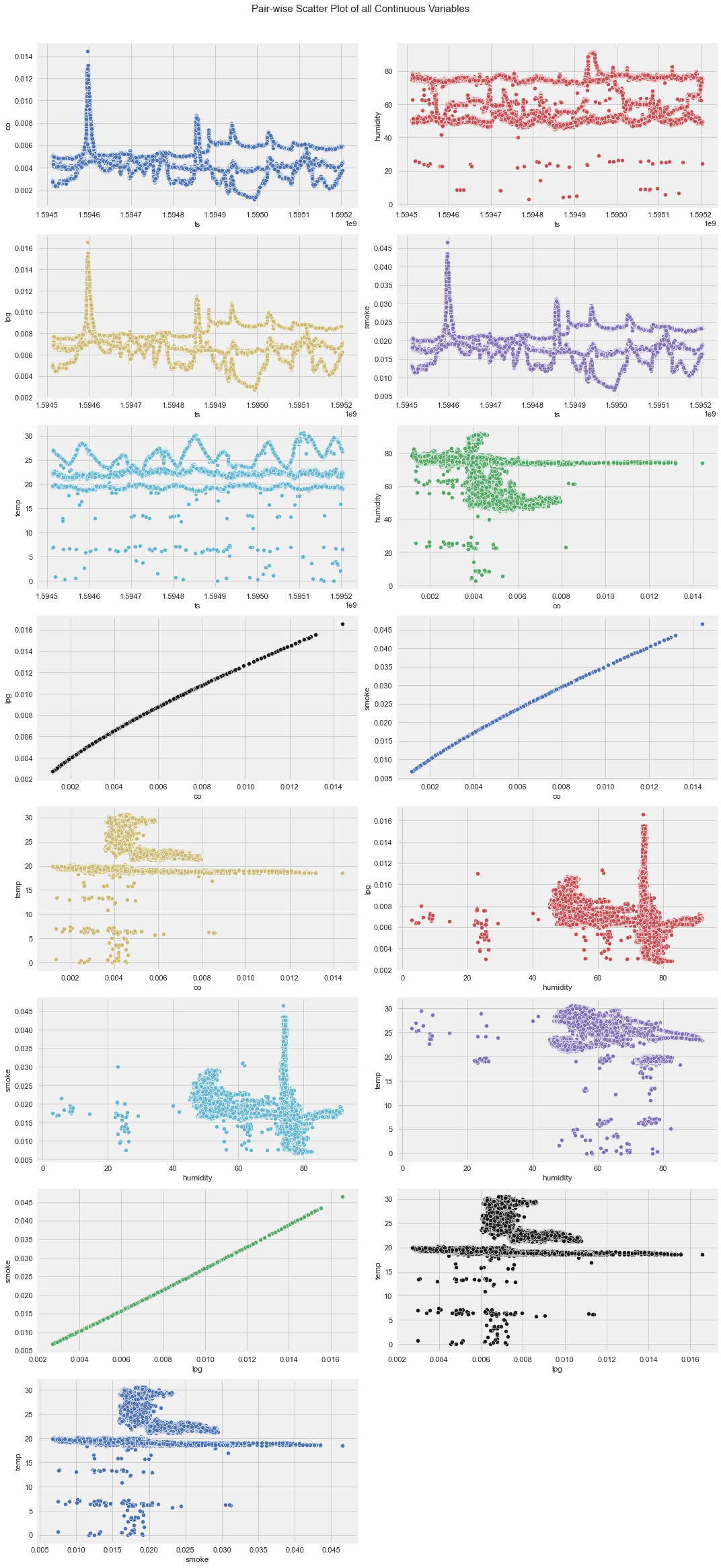
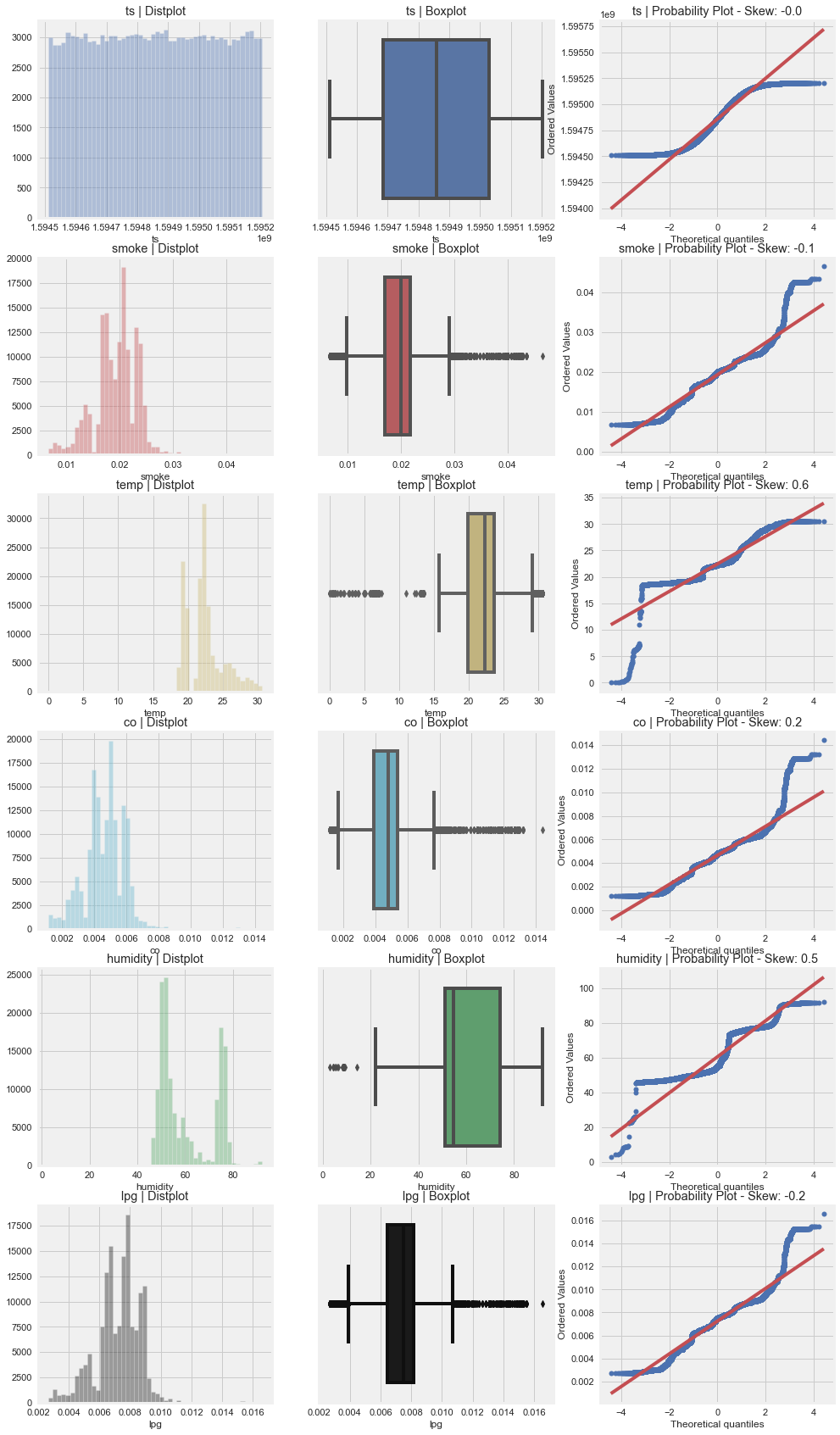
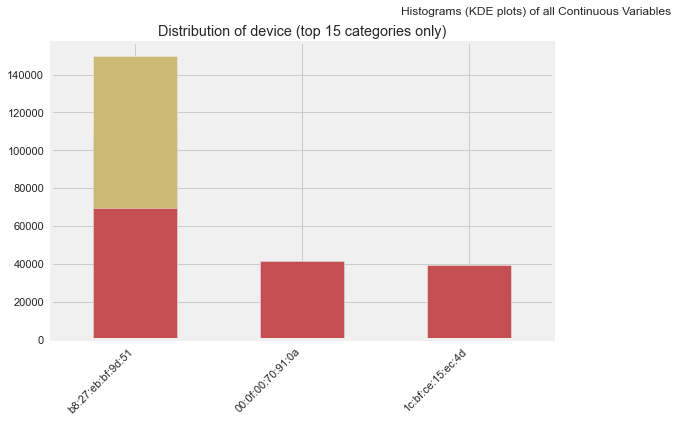
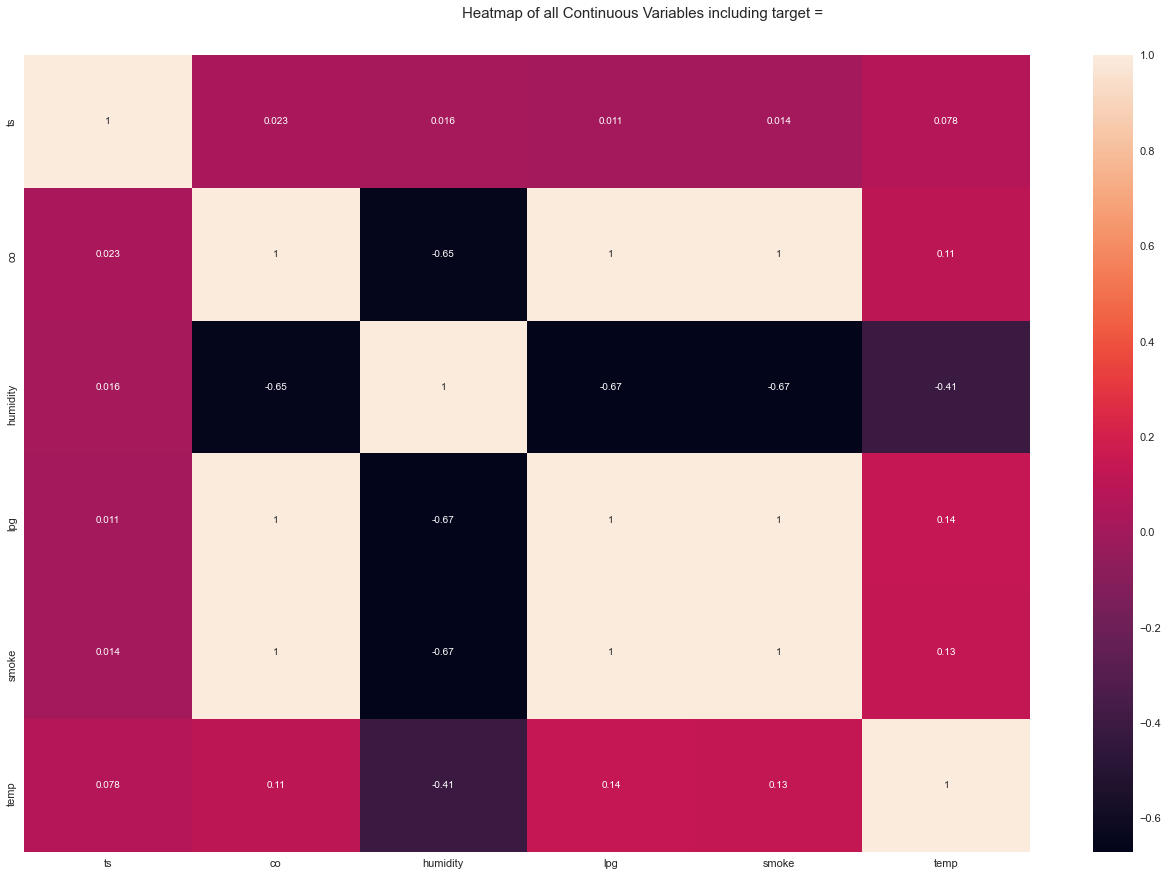

Time to run AutoViz = 35 seconds
###################### AUTO VISUALIZATION Completed ########################As we can see in the above outputs, there are lots of plots to find outliers, relationships and so on. Most of them are done by us manually on earlier steps but if we are on hurry and want to grasp insight as soon as possible, Autoviz is highly recommended. Pandas Profiling is even richer and it gives us interactive way to tune between different aspects of EDA like correlation, null counts, plots and so on. But this blog doesn't contain the result because this is a static blog. 🙂
ProfileReport(dfa)For more of our EDA contents, please follow the link.