Introduction
Alpaca Trading API is an API using which we can retrieve stock data in realtime. It provides various APIs and even streaming services. Please read about it in their docs. What is most exciting about this API and the librariy is that it returns the data as a Pandas Dataframe or even simple Dict object. And here we will focus on how to do real time stock market data retrieval.
Getting API Keys
- To access API, we need to have an account. So lets signup in https://app.alpaca.markets/signup. Then fill up the form and go to the home page.
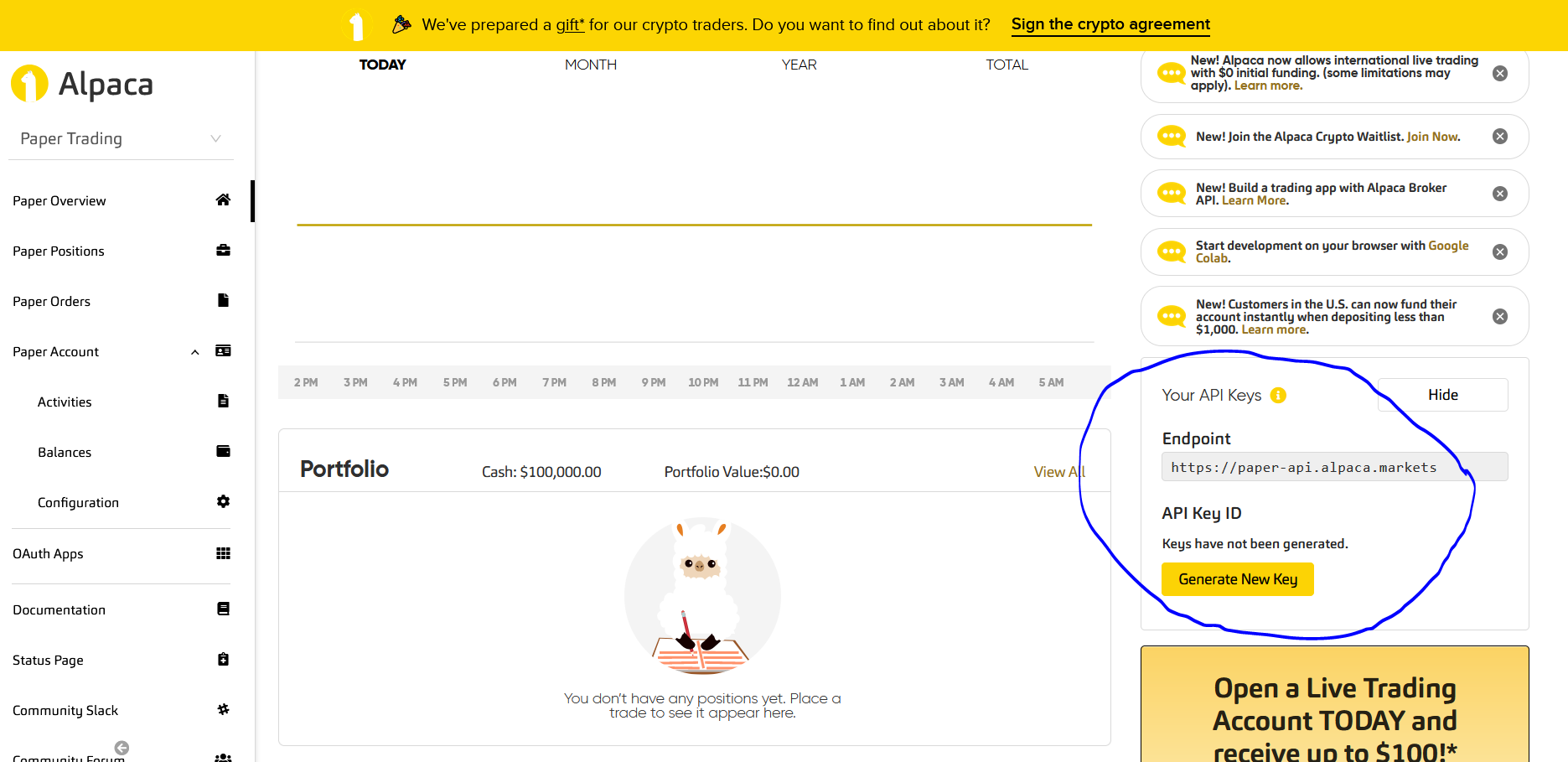
- In order to make first ever API request, we need to have API keys and secret. So go to papertrading and signup for keys. It requires real identity card and live camera at some point.
- Save your API Keys and Secret somewhere safe.
Making First Request
- Install the library first using
pip3 install alpaca-trade-api. Or your own package manager in Python.
!pip3 install alpaca-trade-apiimport pandas as pd
key="PK5OLX1GAB5TYELHCV1J"
secret="LFdvHRFf93NydXF2kDAskTKDjHtBPyBHnszciU4G"
Please insert your generated keys in above variable.
import alpaca_trade_api as tradeapi
# to which url we will send request
base_url="https://paper-api.alpaca.markets"
# instantiate REST API
api = tradeapi.REST(key, secret, base_url, api_version='v2')
# obtain account information
account = api.get_account()
print(account)Account({ 'account_blocked': False,
'account_number': 'PA3BQI9QBTE3',
'accrued_fees': '0',
'buying_power': '200000',
'cash': '100000',
'created_at': '2022-04-30T14:29:12.722985Z',
'crypto_status': 'ACTIVE',
'currency': 'USD',
'daytrade_count': 0,
'daytrading_buying_power': '0',
'equity': '100000',
'id': 'ddeb8bc4-87d3-4ade-8b4a-8a40c7207fed',
'initial_margin': '0',
'last_equity': '100000',
'last_maintenance_margin': '0',
'long_market_value': '0',
'maintenance_margin': '0',
'multiplier': '2',
'non_marginable_buying_power': '100000',
'pattern_day_trader': False,
'pending_transfer_in': '0',
'portfolio_value': '100000',
'regt_buying_power': '200000',
'short_market_value': '0',
'shorting_enabled': True,
'sma': '0',
'status': 'ACTIVE',
'trade_suspended_by_user': False,
'trading_blocked': False,
'transfers_blocked': False})It shows that the fresh new account that I just created.
Getting List of Symbols
We can get the list of assets like below.
active_assets=api.list_assets(status='active')
for asset in active_assets:
print(asset)
breakAsset({ 'class': 'us_equity',
'easy_to_borrow': False,
'exchange': 'OTC',
'fractionable': False,
'id': 'f377f9ef-4b3b-425d-890d-dc7698edc623',
'marginable': False,
'name': 'GWG HLDGS INC Common Stock',
'shortable': False,
'status': 'active',
'symbol': 'GWGHQ',
'tradable': False})Rest APIs
Alpaca provides various REST APIs that handles the most common requests like getting trade, quote, floorsheet.
Get Floorsheet Data
Now is the time to make first request to get data. So lets define a list of stock symbols that we will be focusing on. We will focus on Tesla and Apple stocks. And we want to see floorsheet value of each minute.
In terms of Alpaca, its bars.
All At one time
We can get all data at one time or iterate over it. Getting all data is little bit slow and might require extra memory.
symbols = ["TSLA", "AAPL"]
resp = api.get_bars(symbols,timeframe='1Min', start="2022-04-30",limit=10000)
resp.df.reset_index()| index |
|---|
Today is Friday and hence there will not be any data at the moment. Thus, we will need to change start date to yesterday.
symbols = ["TSLA", "AAPL"]
resp = api.get_bars(symbols,timeframe='1Min', start="2022-04-29",limit=None)
resp.df.reset_index()| timestamp | open | high | low | close | volume | trade_count | vwap | symbol | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2022-04-29 08:00:00+00:00 | 161.00 | 161.50 | 160.36 | 160.36 | 6107 | 116 | 160.736835 | AAPL |
| 1 | 2022-04-29 08:01:00+00:00 | 160.74 | 160.84 | 160.70 | 160.77 | 3929 | 87 | 160.773235 | AAPL |
| 2 | 2022-04-29 08:02:00+00:00 | 160.84 | 160.84 | 160.77 | 160.77 | 2929 | 69 | 160.803947 | AAPL |
| 3 | 2022-04-29 08:03:00+00:00 | 160.75 | 160.77 | 160.70 | 160.77 | 3335 | 71 | 160.734747 | AAPL |
| 4 | 2022-04-29 08:04:00+00:00 | 160.78 | 160.98 | 160.77 | 160.98 | 1496 | 42 | 160.826170 | AAPL |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1726 | 2022-04-29 23:55:00+00:00 | 876.68 | 876.68 | 876.68 | 876.68 | 432 | 36 | 876.634097 | TSLA |
| 1727 | 2022-04-29 23:56:00+00:00 | 876.64 | 877.00 | 876.64 | 877.00 | 3178 | 65 | 876.884078 | TSLA |
| 1728 | 2022-04-29 23:57:00+00:00 | 877.00 | 877.00 | 876.80 | 877.00 | 1599 | 87 | 877.110913 | TSLA |
| 1729 | 2022-04-29 23:58:00+00:00 | 878.00 | 878.02 | 877.58 | 877.58 | 1431 | 100 | 877.933099 | TSLA |
| 1730 | 2022-04-29 23:59:00+00:00 | 877.88 | 877.88 | 877.50 | 877.50 | 1299 | 90 | 877.808984 | TSLA |
1731 rows × 9 columns
Now looking over the dataframe above, we can see that there are 1731 rows with floorsheet value of each minute for each stock.
Custom Timeframe
We can even get floorsheet data of every 45, 10, 30 minute or even more customized using TimeFrame and TimeFrameUnit given by its package.
from alpaca_trade_api.rest import TimeFrame, TimeFrameUnit
df = api.get_bars(symbols, TimeFrame(13, TimeFrameUnit.Minute), "2022-04-29").df.reset_index()
df| timestamp | open | high | low | close | volume | trade_count | vwap | symbol | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2022-04-29 07:57:00+00:00 | 161.00 | 161.50 | 160.36 | 160.62 | 46766 | 847 | 160.805158 | AAPL |
| 1 | 2022-04-29 08:10:00+00:00 | 160.63 | 160.78 | 160.52 | 160.56 | 53331 | 755 | 160.655755 | AAPL |
| 2 | 2022-04-29 08:23:00+00:00 | 160.56 | 160.63 | 159.63 | 160.00 | 72334 | 1059 | 160.035541 | AAPL |
| 3 | 2022-04-29 08:36:00+00:00 | 159.92 | 160.00 | 159.85 | 160.00 | 15276 | 349 | 159.939272 | AAPL |
| 4 | 2022-04-29 08:49:00+00:00 | 159.96 | 160.00 | 159.74 | 159.80 | 14169 | 347 | 159.896077 | AAPL |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 145 | 2022-04-29 23:07:00+00:00 | 877.26 | 877.71 | 876.09 | 876.24 | 6727 | 335 | 877.222977 | TSLA |
| 146 | 2022-04-29 23:20:00+00:00 | 875.20 | 875.60 | 875.01 | 875.60 | 2143 | 187 | 875.371510 | TSLA |
| 147 | 2022-04-29 23:33:00+00:00 | 875.57 | 876.50 | 875.57 | 876.50 | 9723 | 443 | 876.288069 | TSLA |
| 148 | 2022-04-29 23:46:00+00:00 | 876.50 | 878.02 | 876.49 | 877.58 | 11632 | 507 | 876.892889 | TSLA |
| 149 | 2022-04-29 23:59:00+00:00 | 877.88 | 877.88 | 877.50 | 877.50 | 1299 | 90 | 877.808984 | TSLA |
150 rows × 9 columns
In above example, we are looking for floorsheet of every 13 minutes. We can even use Hour there.
Iterating Over
Instead of getting entire data, it might be a good idea to loop through if we have many rows. Thus we can get a iterable and iterate over it like below.
fls = api.get_bars_iter(symbols, TimeFrame(10, TimeFrameUnit.Hour), "2022-04-29")
for fs in fls:
print(fs)Bar({ 'S': 'AAPL',
'c': 160.01,
'h': 166.2,
'l': 158.97,
'n': 699101,
'o': 161,
't': '2022-04-29T08:00:00Z',
'v': 75360694,
'vw': 162.450706})
Bar({ 'S': 'AAPL',
'c': 157.93,
'h': 160.39,
'l': 157.25,
'n': 323819,
'o': 160,
't': '2022-04-29T18:00:00Z',
'v': 56041611,
'vw': 158.373787})
Bar({ 'S': 'TSLA',
'c': 891.86,
'h': 934.3999,
'l': 884.46,
'n': 651589,
'o': 899,
't': '2022-04-29T08:00:00Z',
'v': 20826462,
'vw': 910.364386})
Bar({ 'S': 'TSLA',
'c': 877.5,
'h': 892.81,
'l': 868,
'n': 222398,
'o': 891.88,
't': '2022-04-29T18:00:00Z',
'v': 8468767,
'vw': 878.750304})Getting Quotes
Quotes are the biddings that has been done.
df = api.get_quotes(symbols, start="2022-04-29",limit=1000).df.reset_index()
df| timestamp | ask_exchange | ask_price | ask_size | bid_exchange | bid_price | bid_size | conditions | tape | symbol | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2022-04-29 08:00:00.001169445+00:00 | 0.00 | 0 | Q | 160.66 | 4 | [Y] | C | AAPL | |
| 1 | 2022-04-29 08:00:00.001241377+00:00 | Q | 160.93 | 4 | Q | 160.66 | 4 | [R] | C | AAPL |
| 2 | 2022-04-29 08:00:00.005655+00:00 | Q | 160.93 | 4 | K | 161.50 | 1 | [R] | C | AAPL |
| 3 | 2022-04-29 08:00:00.005655+00:00 | Q | 160.93 | 4 | Q | 160.66 | 4 | [R] | C | AAPL |
| 4 | 2022-04-29 08:00:00.005655+00:00 | Q | 160.93 | 4 | K | 161.00 | 1 | [R] | C | AAPL |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 995 | 2022-04-29 08:22:05.119679488+00:00 | P | 160.55 | 2 | Q | 160.52 | 1 | [R] | C | AAPL |
| 996 | 2022-04-29 08:22:05.119927355+00:00 | Q | 160.59 | 6 | Q | 160.55 | 1 | [R] | C | AAPL |
| 997 | 2022-04-29 08:22:05.119937180+00:00 | Q | 160.59 | 6 | P | 160.52 | 1 | [R] | C | AAPL |
| 998 | 2022-04-29 08:22:05.120335360+00:00 | P | 160.55 | 1 | Q | 160.52 | 1 | [R] | C | AAPL |
| 999 | 2022-04-29 08:22:05.120487168+00:00 | P | 160.55 | 3 | Q | 160.52 | 1 | [R] | C | AAPL |
1000 rows × 10 columns
There are various fileds and there is a well described documentation in docs.
Getting Trade
To view the trades that has actually happened.
df = api.get_trades(symbols, start="2022-04-29",limit=1000).df.reset_index()
df| timestamp | exchange | price | size | conditions | id | tape | symbol | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2022-04-29 04:00:13.553000+00:00 | D | 160.09 | 1 | [@, T, I] | 927 | C | AAPL |
| 1 | 2022-04-29 04:00:43.779000+00:00 | D | 160.09 | 220 | [@, T] | 871 | C | AAPL |
| 2 | 2022-04-29 04:02:52.730000+00:00 | D | 160.10 | 1 | [@, T, I] | 912 | C | AAPL |
| 3 | 2022-04-29 04:02:52.730000+00:00 | D | 160.10 | 4 | [@, T, I] | 940 | C | AAPL |
| 4 | 2022-04-29 04:06:04.276000+00:00 | D | 160.10 | 20 | [@, T, I] | 941 | C | AAPL |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 995 | 2022-04-29 08:09:30.317838547+00:00 | Q | 160.63 | 1 | [@, F, T, I] | 430 | C | AAPL |
| 996 | 2022-04-29 08:09:30.617365760+00:00 | P | 160.61 | 137 | [@, F, T] | 258 | C | AAPL |
| 997 | 2022-04-29 08:09:30.617365760+00:00 | P | 160.60 | 74 | [@, F, T, I] | 259 | C | AAPL |
| 998 | 2022-04-29 08:09:30.756697344+00:00 | P | 160.60 | 2 | [@, T, I] | 260 | C | AAPL |
| 999 | 2022-04-29 08:09:32.422441+00:00 | K | 160.60 | 10 | [@, F, T, I] | 129 | C | AAPL |
1000 rows × 8 columns
Alpaca provides other Rest APIs too which can be seen in their module https://github.com/alpacahq/alpaca-trade-api-python/blob/master/alpaca_trade_api/rest.py. Most of the REST APIs have iterable functions too like get_bars_iter, get_quote_iter.
Streaming Data
Streaming Data is done to get realtime data and Alpaca provides websockets to do that. To do so, we will use async keyword in front of the function that will be awaitable. Below code is taken from the GitHub repo of Alpaca package.
from alpaca_trade_api.stream import Stream
from alpaca_trade_api.common import URL
async def trade_callback(t):
print('trade', t)
async def quote_callback(q):
print('quote', q)
# Initiate Class Instance
stream = Stream(key,
secret,
base_url=URL('https://paper-api.alpaca.markets'),
data_feed='iex')
# subscribing to event
stream.subscribe_trades(trade_callback, 'AAPL')
stream.subscribe_quotes(quote_callback, 'IBM')
stream.run()There are some other streamming APIs also like subscribe_bars which can be seen inside a module stream.py.
How to stream bars data?
By default there is not a possibility to stream a bars data but one can do it by using asyncio in Python.
This section will be updated soon. Sorry.
async def get_bars(symbols, start_time,timeframe="1Min"):
tm = int(timeframe.split("Min")[0])
end_time=None
sym=None
dump_table=f"bars_{timeframe.split('Min')[0]}m"
try:
while True:
print(f"Start Time: {start_time} End Time {end_time} Timeframe: {timeframe}")
resp = api.get_bars_iter(symbols,start=start_time,end=end_time, timeframe=timeframe)
for r in resp:
print(r)
sym=r.symbol
sym=symbol
if start_time==timestamp.isoformat() and sym==symbol:
logger.info(f"Start Time == End Time: {start_time} == {timestamp}. Sleeping for {tm} minutes")
await asyncio.sleep(tm*60)
start_time=timestamp.isoformat()
end_time=timestamp+timedelta(days=2)
end_time=end_time.isoformat()
print("-----------------------------------------------------")
print("Setting start time to: ", timestamp)
clock = api.get_clock()
next_open = clock.next_open
curr_day = fdate.strftime("%A")
if clock.is_open==False:
sleep_seconds = (clock.next_open-clock.timestamp).total_seconds()
sleep_hours = sleep_seconds/(3600)
logger.info(f"Market is closed. Market Opens on {clock.next_open}. Sleeping for {sleep_hours} hrs.")
await asyncio.sleep(sleep_seconds)
else:
logger.info(f"No new data available. Sleeping for {tm} Minutes")
await asyncio.sleep(tm*60)
except Exception as e:
print(f"Error {e} in {timeframe}, {start_time}")
async def stream_mbars():
rdate=date.today()-timedelta(days=2)
allow_symbols = ["TSLA", "AAPL"]
await asyncio.gather(
get_bars(allow_symbols,rdate,timeframe="1Min"),
get_bars(allow_symbols,rdate, timeframe="2Min"),
get_bars(allow_symbols,rdate, timeframe="3Min"),
get_bars(allow_symbols,rdate, timeframe="5Min"),
)
def main_stream():
asyncio.run(stream_mbars())
loop = asyncio.get_event_loop()
loop.run_until_complete(stream_mbars())In above code, there are 3 functions and we will call the main_stream() function. It runs the stream_mbars event and it also runs other events like get_bars. It is little bit messy but lets explain it little:
- The program never ends as there is
while Trueis in theget_barsfunction. - However,
get_barsis allowed to sleep when market is close, or no new data is available. Which means that if we are going to get5mbars, then running it for each minute is not a good idea instead we need to run it every 5 minutes. So it will sleep for 5mins. - The data is retrieved from the iterator because it is much safer as it takes less memory.
- After an iterator completes, we set the end time to two days from last timestamp. Its sure that there will not be any data for 2 days from last timestamp. But still.
In my original production side code, I have stored all these data into table and later used it to calculate indicators and based on the indicators, I make alerts and for the alerts, I have number of rules. If the alert is True in any time then I get mail of it. Phew.....