Introduction
Hello there, this is the part 5 of Python for Stock Market Analysis and in this part, we will continue from where we left i.e. modeling a timeseries. Finding a best set of parameters that gives highly accurate prediction is always a hard job and there is not always a guarantee that one can find the best parameters. There are few reasons due to which we can not find best parameters of timeseries model:
- Series can be resembling white noise.
- Series can be random walk.
- External variables (Exogenous) could be in action.
But with assuming that we are ready to break above problems, lets get into modeling.
import pandas as pd
import plotly.express as px
import cufflinks
import plotly.io as pio
import yfinance as yf
import warnings
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
from statsmodels.tsa.arima_model import ARMA, ARIMA
import statsmodels.api as sm
warnings.filterwarnings("ignore")
cufflinks.go_offline()
cufflinks.set_config_file(world_readable=True, theme='pearl')
pio.renderers.default = "notebook" # should change by looking into pio.renderers
sns.set(rc={'figure.figsize':(40, 20)})
plt.rc("figure", figsize=(16,8))
pd.options.display.max_columns = Nonesymbols = ["AAPL"]
df = yf.download(tickers=symbols,start="2002-02-01")
df.columns = [c.lower() for c in df.columns]
df.rename(columns={"adj close":"adj_close"},inplace=True)
df.head()NumExpr defaulting to 8 threads.
[*********************100%***********************] 1 of 1 completed| open | high | low | close | adj_close | volume | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 2002-01-31 | 0.431429 | 0.441607 | 0.430536 | 0.441429 | 0.377984 | 468445600 |
| 2002-02-01 | 0.434643 | 0.445714 | 0.434643 | 0.435893 | 0.373244 | 398305600 |
| 2002-02-04 | 0.434286 | 0.455714 | 0.432143 | 0.452679 | 0.387617 | 522373600 |
| 2002-02-05 | 0.448036 | 0.463929 | 0.447857 | 0.454464 | 0.389146 | 456887200 |
| 2002-02-06 | 0.457143 | 0.463929 | 0.431250 | 0.440536 | 0.377220 | 597576000 |
Metrics
def percentage_change(forecast, actual, threshold=10):
pchange = 100*(forecast-actual)/actual
acc = (pchange.abs()<threshold).sum()/len(pchange)
return acc
def mean_squared(forecast, actual):
return np.mean((forecast - actual)**2)Auto Regression (AR)
Auto regression is nothing more than a linear relationship of a series with lagged version of itself.
Formula to represent AR model is:
$$
xt = c + \phi.x{(t-1)} + \epsilon_t
$$
Where,
- c is constant.
- xt is the current value.
- x_(t-1) is the value of previous period.
- 𝜖𝑡 is the residual value.
If data is from non stationarity process then AR models fails.
The value of lag should be chosen by examining the PACF plot i.e choose last significant value of lag before it becomes insignificant.
plot_pacf(df.adj_close)
plt.plot()[]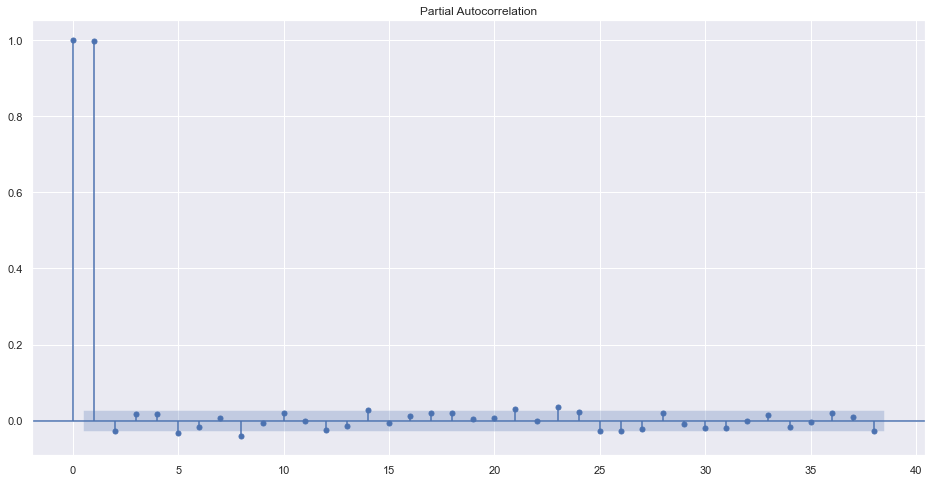
It seems that after the first lag, the values became insignificant. So the best order of AR can be 1.
LLR Test
To check if two models are significantly different or not. If the p-value is lower than 5%, then we should choose the later model. Always use simpler model at first. The degree of freedom is chosen by subtracting order values.
from scipy.stats.distributions import chi2
def LLR_test(mod1, mod2, degf=1):
l1 = mod1.fit().llf
l2 = mod2.fit().llf
lr = (2*(l2-l1))
p = chi2.sf(lr, degf).round(3)
return prmodel1 = ARMA(df.adj_close, order=(1, 0))
rresults1 = rmodel1.fit()
print(rresults1.summary())
rmodel3 = ARMA(df.adj_close, order=(2, 0))
rresults3 = rmodel3.fit()
print(rresults3.summary())
LLR_test(rmodel1, rmodel3, 1) ARMA Model Results
==============================================================================
Dep. Variable: adj_close No. Observations: 5088
Model: ARMA(1, 0) Log Likelihood -6715.633
Method: css-mle S.D. of innovations 0.904
Date: Sat, 16 Apr 2022 AIC 13437.266
Time: 12:59:22 BIC 13456.870
Sample: 0 HQIC 13444.131
===================================================================================
coef std err z P>|z| [0.025 0.975]
-----------------------------------------------------------------------------------
const 27.7966 nan nan nan nan nan
ar.L1.adj_close 1.0000 nan nan nan nan nan
Roots
=============================================================================
Real Imaginary Modulus Frequency
-----------------------------------------------------------------------------
AR.1 1.0000 +0.0000j 1.0000 0.0000
-----------------------------------------------------------------------------
ARMA Model Results
==============================================================================
Dep. Variable: adj_close No. Observations: 5088
Model: ARMA(2, 0) Log Likelihood -6712.381
Method: css-mle S.D. of innovations 0.903
Date: Sat, 16 Apr 2022 AIC 13432.761
Time: 12:59:22 BIC 13458.900
Sample: 0 HQIC 13441.914
===================================================================================
coef std err z P>|z| [0.025 0.975]
-----------------------------------------------------------------------------------
const 27.7475 nan nan nan nan nan
ar.L1.adj_close 0.9611 7.05e-06 1.36e+05 0.000 0.961 0.961
ar.L2.adj_close 0.0389 7.33e-07 5.31e+04 0.000 0.039 0.039
Roots
=============================================================================
Real Imaginary Modulus Frequency
-----------------------------------------------------------------------------
AR.1 1.0000 +0.0000j 1.0000 0.0000
AR.2 -25.6971 +0.0000j 25.6971 0.5000
-----------------------------------------------------------------------------
0.011It seems that the model with order 2 is slightly more significant than of order 1. But lets check with 3rd order and second.
rmodel1 = ARMA(df.adj_close, order=(2, 0))
rresults1 = rmodel1.fit()
print(rresults1.summary())
rmodel3 = ARMA(df.adj_close, order=(3, 0))
rresults3 = rmodel3.fit()
print(rresults3.summary())
LLR_test(rmodel1, rmodel3, 1) ARMA Model Results
==============================================================================
Dep. Variable: adj_close No. Observations: 5088
Model: ARMA(2, 0) Log Likelihood -6712.381
Method: css-mle S.D. of innovations 0.903
Date: Sat, 16 Apr 2022 AIC 13432.761
Time: 12:59:24 BIC 13458.900
Sample: 0 HQIC 13441.914
===================================================================================
coef std err z P>|z| [0.025 0.975]
-----------------------------------------------------------------------------------
const 27.7475 nan nan nan nan nan
ar.L1.adj_close 0.9611 7.05e-06 1.36e+05 0.000 0.961 0.961
ar.L2.adj_close 0.0389 7.33e-07 5.31e+04 0.000 0.039 0.039
Roots
=============================================================================
Real Imaginary Modulus Frequency
-----------------------------------------------------------------------------
AR.1 1.0000 +0.0000j 1.0000 0.0000
AR.2 -25.6971 +0.0000j 25.6971 0.5000
-----------------------------------------------------------------------------
ARMA Model Results
==============================================================================
Dep. Variable: adj_close No. Observations: 5088
Model: ARMA(3, 0) Log Likelihood -6711.479
Method: css-mle S.D. of innovations 0.903
Date: Sat, 16 Apr 2022 AIC 13432.958
Time: 12:59:26 BIC 13465.631
Sample: 0 HQIC 13444.399
===================================================================================
coef std err z P>|z| [0.025 0.975]
-----------------------------------------------------------------------------------
const 27.7084 nan nan nan nan nan
ar.L1.adj_close 0.9610 7.05e-06 1.36e+05 0.000 0.961 0.961
ar.L2.adj_close 0.0358 0.014 2.565 0.010 0.008 0.063
ar.L3.adj_close 0.0033 0.014 0.234 0.815 -0.024 0.031
Roots
=============================================================================
Real Imaginary Modulus Frequency
-----------------------------------------------------------------------------
AR.1 1.0000 -0.0000j 1.0000 -0.0000
AR.2 -5.9821 -16.4548j 17.5084 -0.3055
AR.3 -5.9821 +16.4548j 17.5084 0.3055
-----------------------------------------------------------------------------
0.179It is not significant. Thus we will choose the order of 1 or 2. Lets see the result by making a forecasting.
Train/Test Split
from sklearn.model_selection import train_test_split
train, test = train_test_split(df, test_size=0.1, shuffle=False)
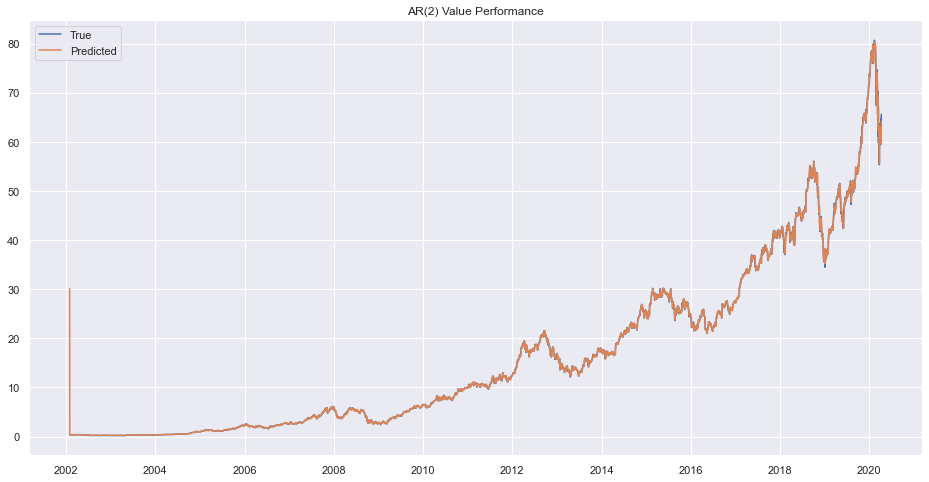
rrmodel1 = ARMA(train.adj_close, order=(2, 0))
rrresults1 = rrmodel1.fit()
# print(rresults1.summary())
# rrresults1.plot_predict(dynamic=False)
# plt.title("AR(2) Model Difference Performance")
# plt.show()
prd = rrresults1.predict()
plt.plot(train.adj_close)
plt.plot(prd)
plt.legend(["True", "Predicted"])
plt.title("AR(2) Value Performance")
plt.show()
prd=rrresults1.forecast(steps=len(test))[0]
prd = pd.Series(prd, index=test.index)
plt.plot(test.adj_close)
plt.plot(prd)
plt.legend(["True", "Predicted"])
plt.title("AR(2) Value Performance")
plt.show()
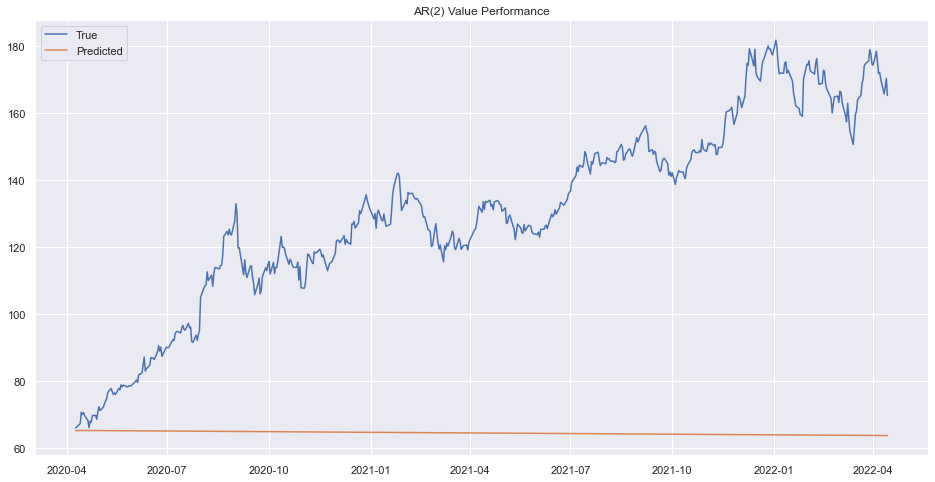
Prediction on train set was okay but not in the test set. lets try another order.
rrmodel1 = ARMA(train.adj_close, order=(1, 0))
rrresults1 = rrmodel1.fit()
prd = rrresults1.predict()
plt.plot(train.adj_close)
plt.plot(prd)
plt.legend(["True", "Predicted"])
plt.title("AR(1) Value Performance")
plt.show()
prd=rrresults1.forecast(steps=len(test))[0]
prd = pd.Series(prd, index=test.index)
plt.plot(test.adj_close)
plt.plot(prd)
plt.legend(["True", "Predicted"])
plt.title("AR(1) Value Performance")
plt.show()
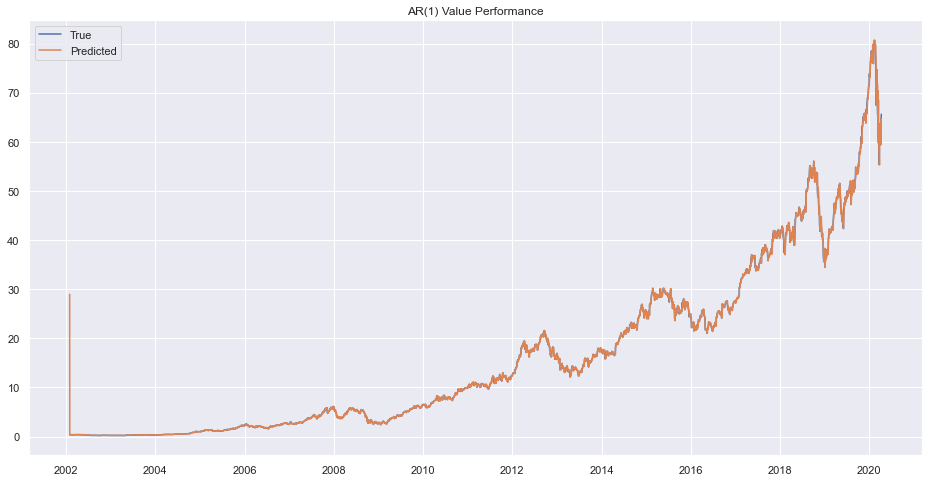
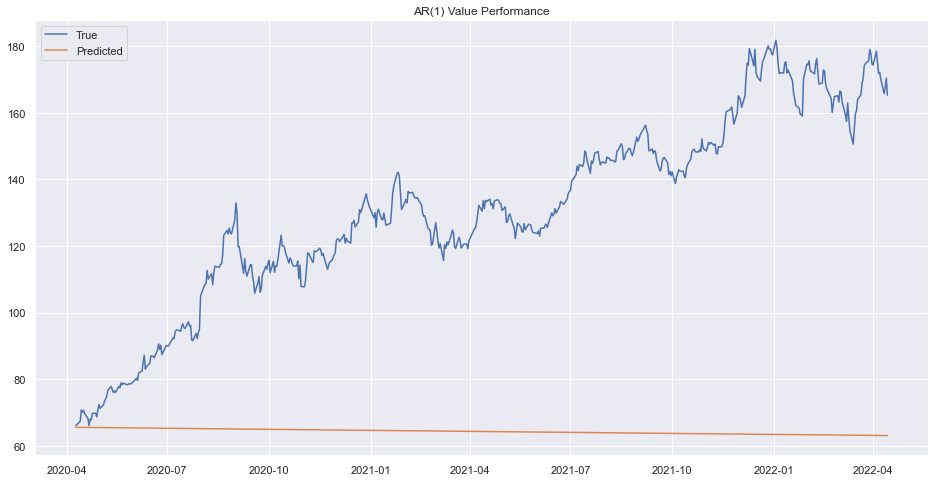
The result is bad. Lets try to find Moving Average Model.
Moving Average (MA)
We have written a good blog about MA in first part of this blog series please refer it for how MA is best idea to look into.
Just like AR model, MA model also uses lag term which is determined using the ACF plot.
$$
r_t = c + \theta1.\epsilon{t-1} + \epsilon_t
$$
Where,
- rt, is value in current period.
- theta, what part of the error last period is relevant in explaining the current value.
- epsilon, error terms of respective time periods.
MA(1) is nearly identical to AR(inf). We can find order of MA using ACF plot.
plot_acf(train.adj_close, lags=365)
plt.plot()[]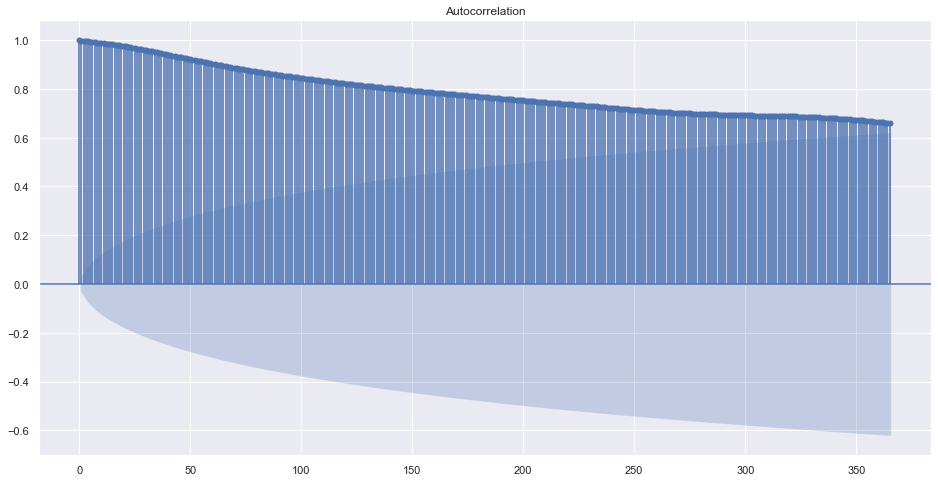
The order of MA is hard to find here because there is not a significant changes but slow decrease of correlation. May be because this is a daily data. What happens in a monthly average?
plot_acf(train.resample("1M").adj_close.mean(), lags=100)
plt.plot()[]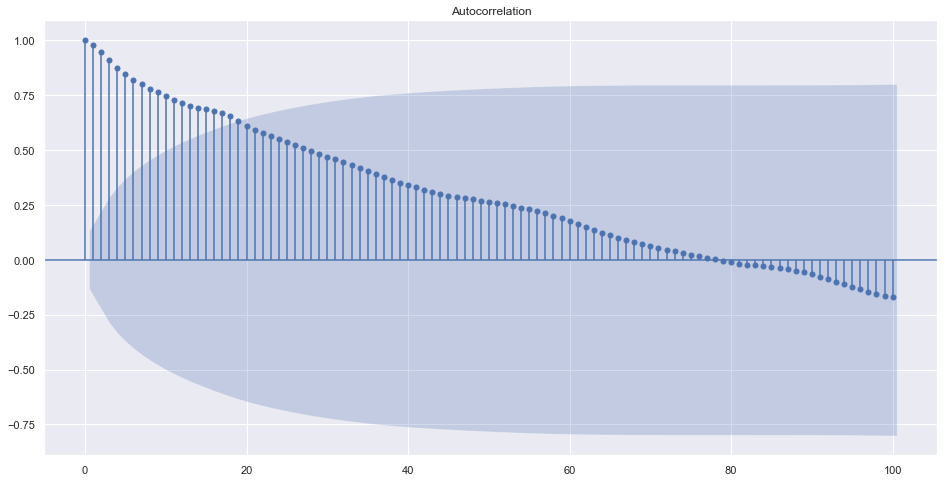
Now we can see that the best order can be below 20 and choices are from 1. ARMA(0,1) is MA(1).
Best MA Model
best=None
pq = 0
for q in range(1,10):
try:
model1 = ARMA(train.adj_close, order=(0, q))
rrresults1 = model1.fit()
if best is None:
best=model1
pq=q
else:
if LLR_test(best, model1, q-pq)<0.05:
best=model1
pq=q
prd = rrresults1.predict()
plt.plot(train.adj_close)
plt.plot(prd)
prd=rrresults1.forecast(steps=len(test))[0]
prd = pd.Series(prd, index=test.index)
plt.plot(test.adj_close)
plt.plot(prd)
plt.legend(["Train True", "Train Predicted", "Test True", "Test Predicted"])
plt.title(f"MA({q}) Value Performance")
plt.show()
except:
print(f"Error on order {q}")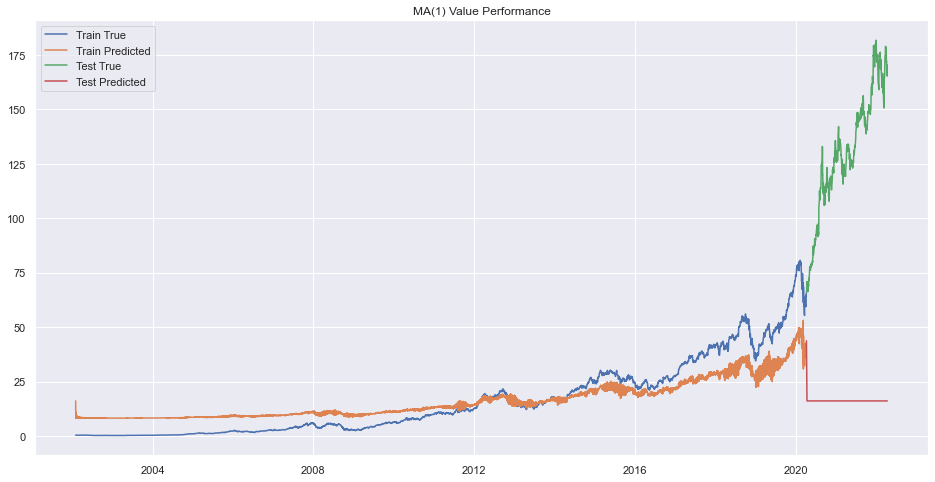
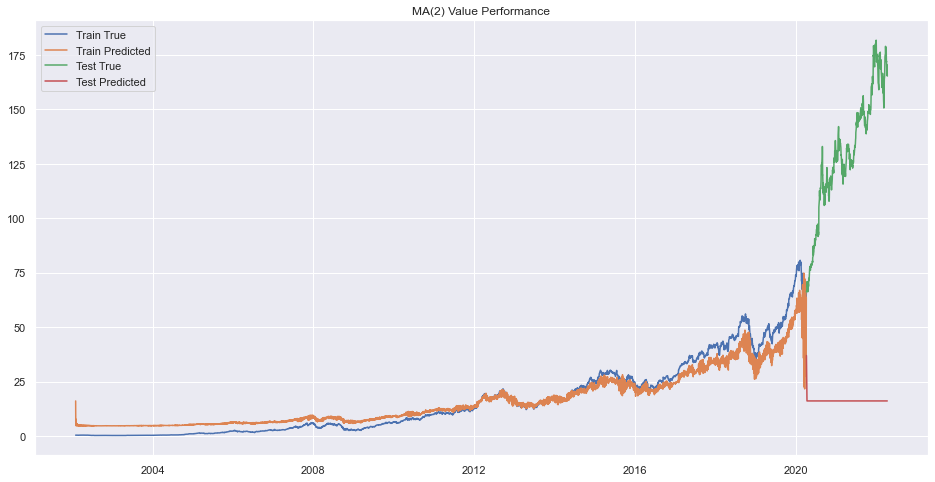
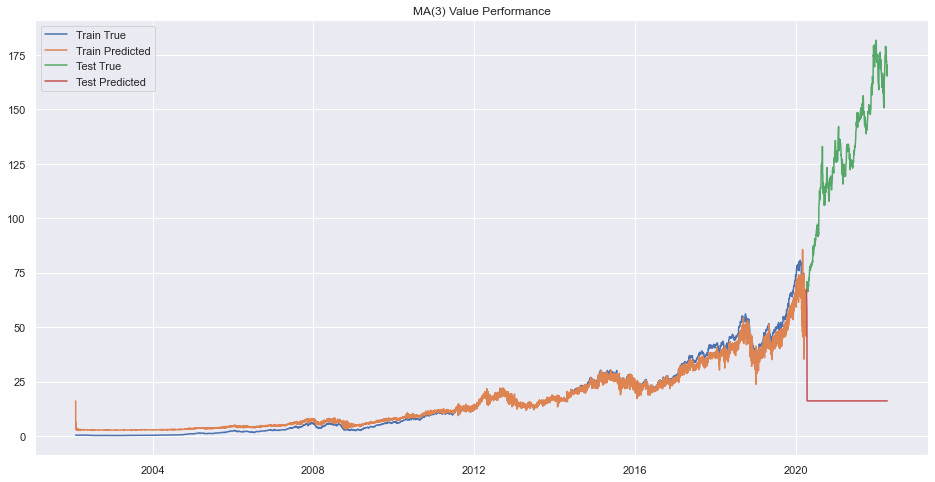
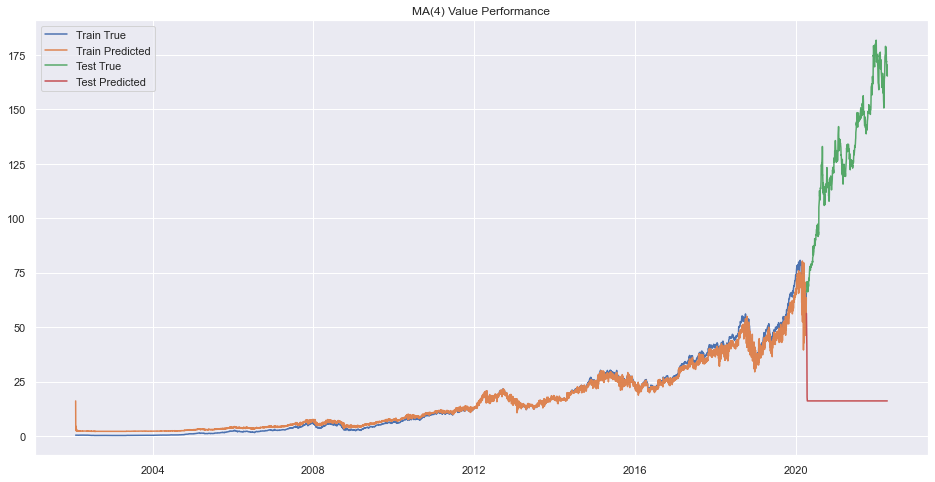
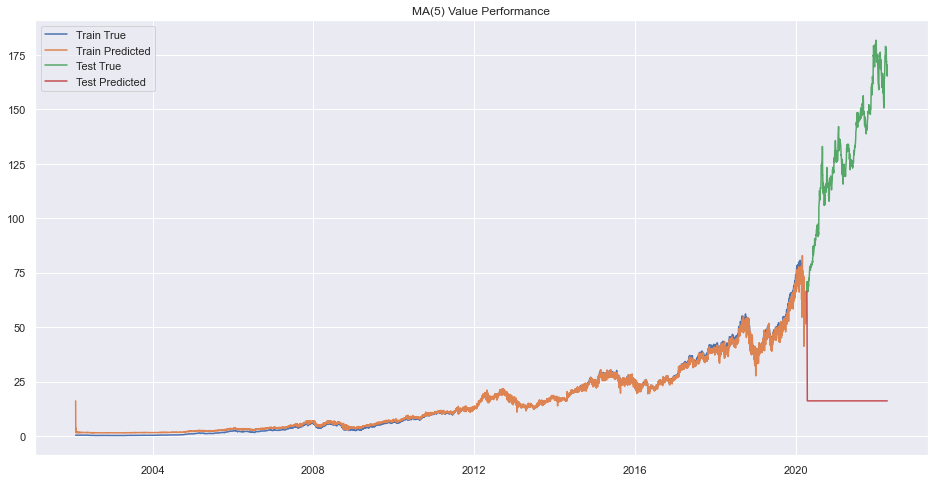
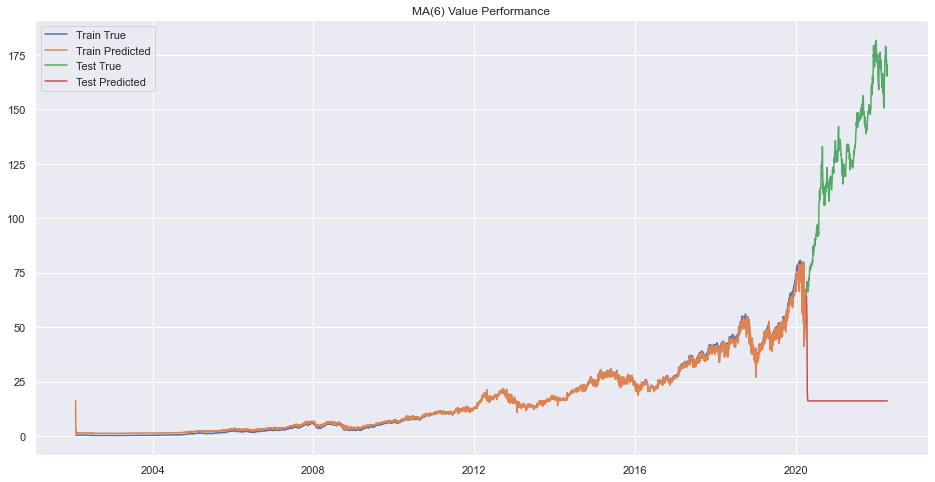
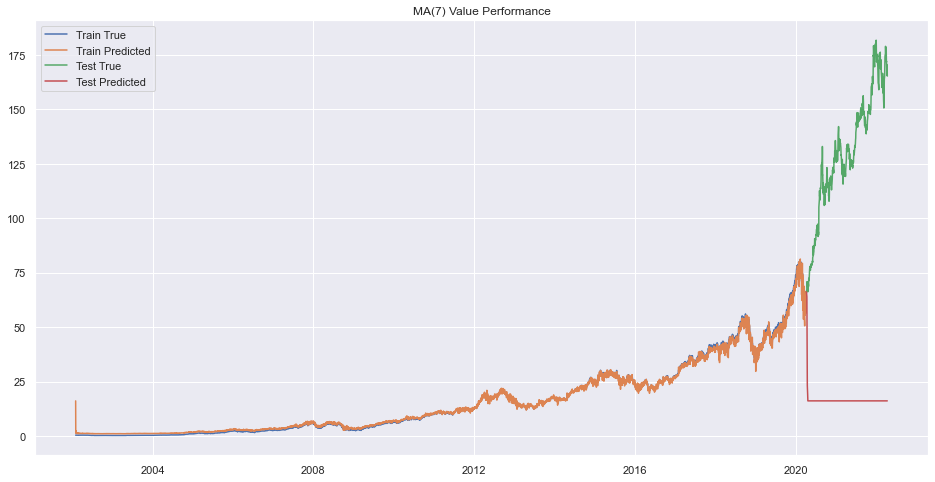
Error on order 8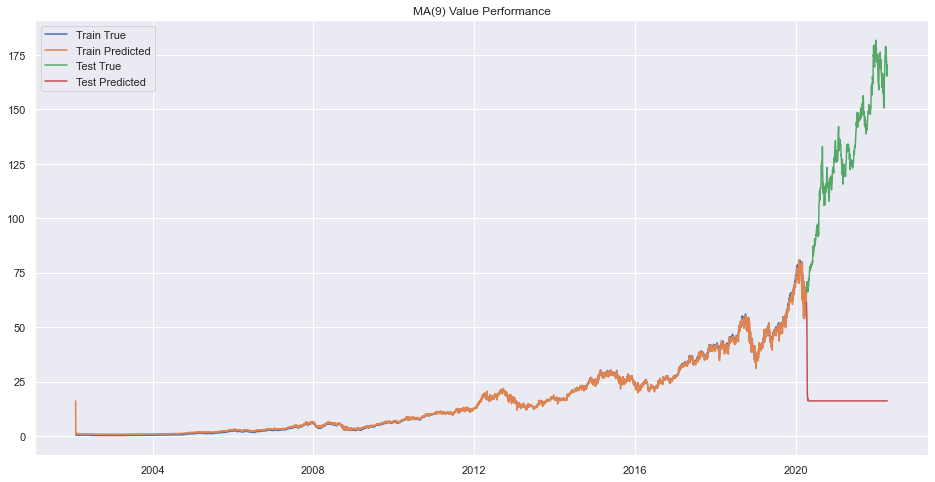
print(f"Best Order is {pq}.")Best Order is 9.There seems to be very bad forecasting but performance on train data was okay.
Auto Regression and Moving Average (ARMA)
It is simple a sum of AR and MA model.
ARMA=AR+MA
Finding Best Orders
best=None
pq = 0
pp = 0
for p in range(1,10):
for q in range(10):
try:
model1 = ARMA(train.adj_close, order=(p, q))
rrresults1 = model1.fit()
if best is None:
best=model1
pq=q
pp = p
else:
if LLR_test(best, model1, q-pq)<0.05:
best=model1
pq=q
pp=p
prd = rrresults1.predict()
plt.plot(train.adj_close)
plt.plot(prd)
prd=rrresults1.forecast(steps=len(test))[0]
prd = pd.Series(prd, index=test.index)
plt.plot(test.adj_close)
plt.plot(prd)
plt.legend(["Train True", "Train Predicted", "Test True", "Test Predicted"])
plt.title(f"ARMA({(p,q)}) Value Performance")
plt.show()
except Exception as e:
# raise e
print(f"Error on order {(p,q)}")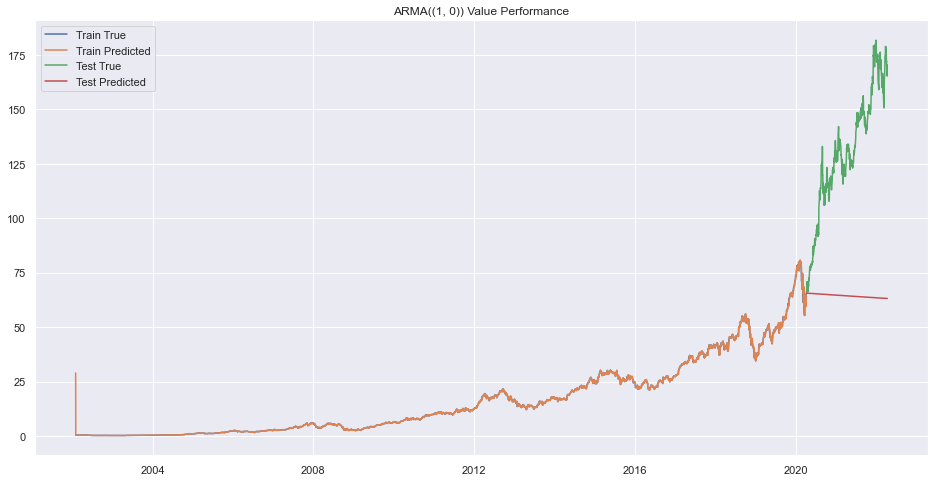
Error on order (1, 1)
Error on order (1, 2)
Error on order (1, 3)
Error on order (1, 4)
Error on order (1, 5)
Error on order (1, 6)
Error on order (1, 7)
Error on order (1, 8)
Error on order (1, 9)
Error on order (2, 1)
Error on order (2, 2)
Error on order (2, 3)
Error on order (2, 4)
Error on order (2, 5)
Error on order (2, 6)
Error on order (2, 7)
Error on order (2, 8)
Error on order (2, 9)
Error on order (3, 1)
Error on order (3, 2)
Error on order (3, 3)
Error on order (3, 4)
Error on order (3, 5)
Error on order (3, 6)
Error on order (3, 7)
Error on order (3, 8)
Error on order (3, 9)
Error on order (4, 1)
Error on order (4, 2)
Error on order (4, 3)
Error on order (4, 4)
Error on order (4, 5)
Error on order (4, 6)
Error on order (4, 7)
Error on order (4, 8)
Error on order (4, 9)
Error on order (5, 1)
Error on order (5, 2)
Error on order (5, 3)
Error on order (5, 4)
Error on order (5, 5)
Error on order (5, 6)
Error on order (5, 7)
Error on order (5, 8)
Error on order (5, 9)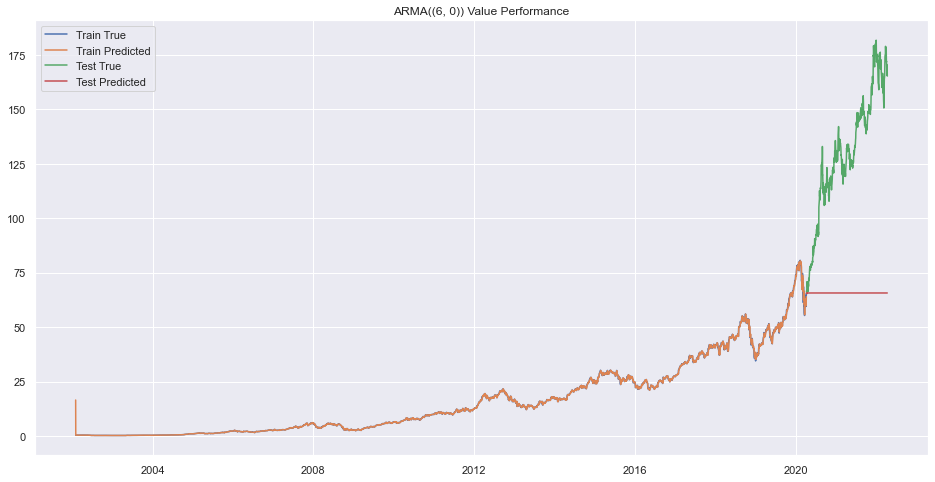
Error on order (6, 1)
Error on order (6, 2)
Error on order (6, 3)
Error on order (6, 4)
Error on order (6, 5)
Error on order (6, 6)
Error on order (6, 7)
Error on order (6, 8)
Error on order (6, 9)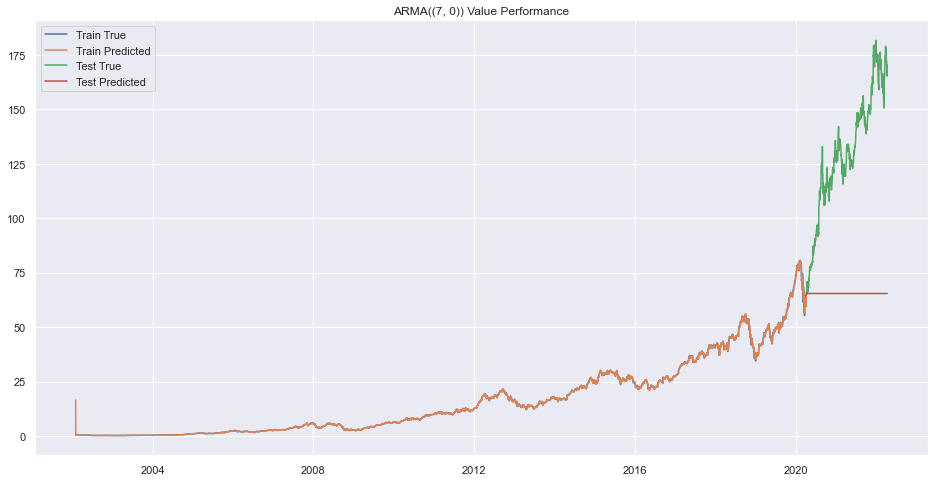
Error on order (7, 1)
Error on order (7, 2)
Error on order (7, 3)
Error on order (7, 4)
Error on order (7, 5)
Error on order (7, 6)
Error on order (7, 7)
Error on order (7, 8)
Error on order (7, 9)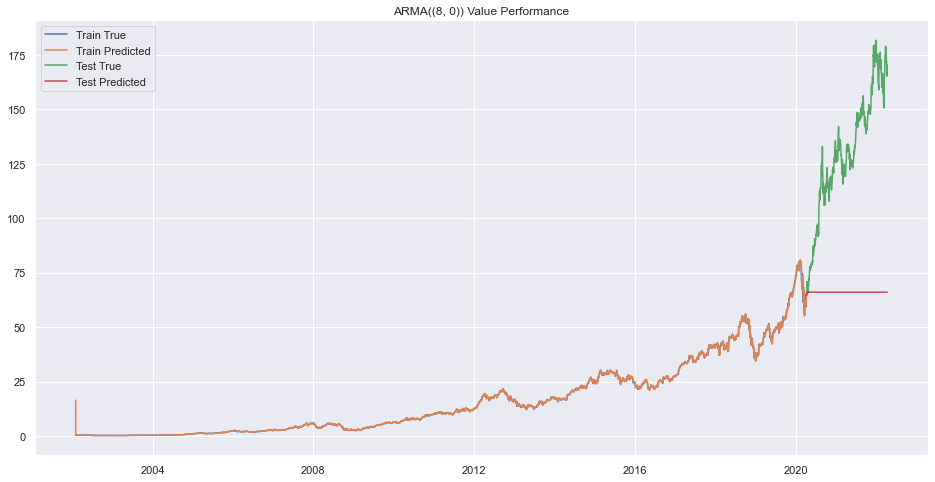
Error on order (8, 1)
Error on order (8, 2)
Error on order (8, 3)
Error on order (8, 4)
Error on order (8, 5)
Error on order (8, 6)
Error on order (8, 7)
Error on order (8, 8)
Error on order (8, 9)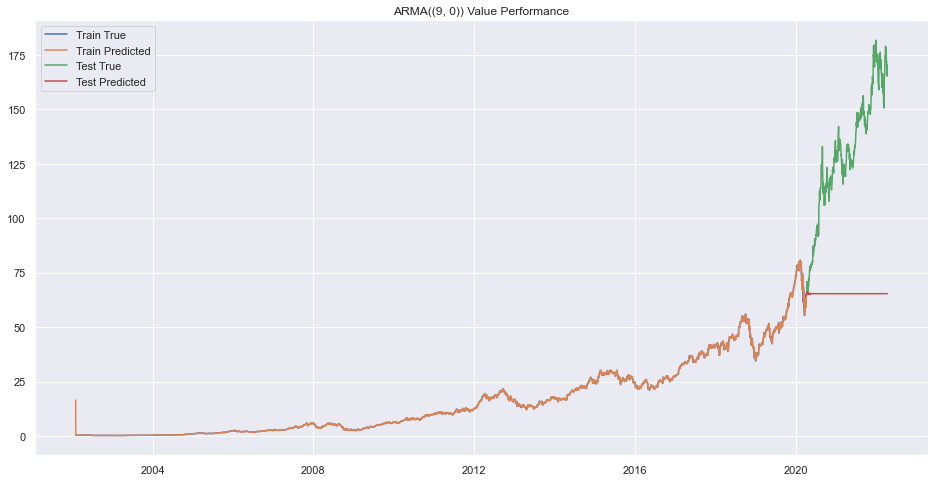
Error on order (9, 1)
Error on order (9, 2)
Error on order (9, 3)
Error on order (9, 4)
Error on order (9, 5)
Error on order (9, 6)
Error on order (9, 7)
Error on order (9, 8)
Error on order (9, 9)ARIMA
Add integration feature to the ARMA. It has 3 values as order, (p, d, q) p from AR, d as integrating order and q as MA order.
How to find differencing term?
The differencing term is needed only if the data is not stationary. Look at the ACF of different order of value.
plot_acf(train.adj_close.diff().dropna(), title="First order")
plot_acf(train.adj_close.diff().diff().dropna(), title="Second order")
plot_acf(train.adj_close.diff().diff().diff().dropna(), title="Third order")
plot_acf(train.adj_close.diff().diff().diff().diff().dropna(), title="Fourth order")
plt.show()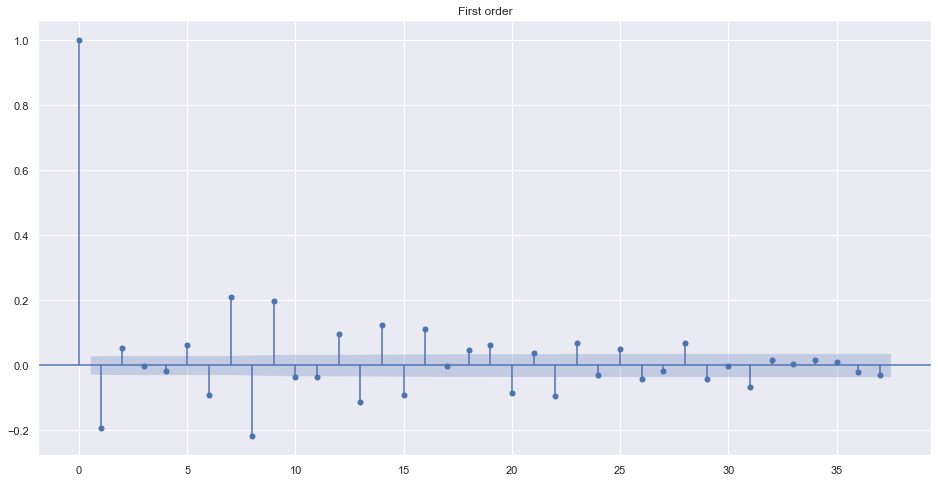
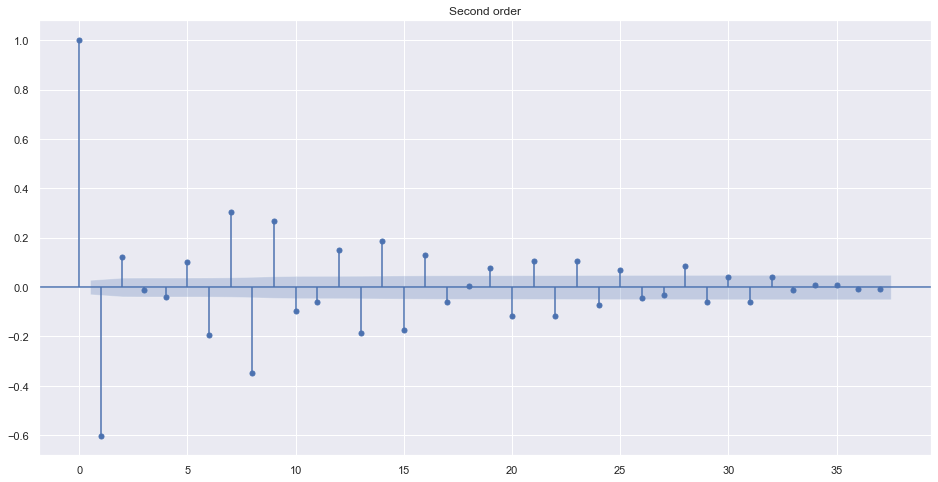
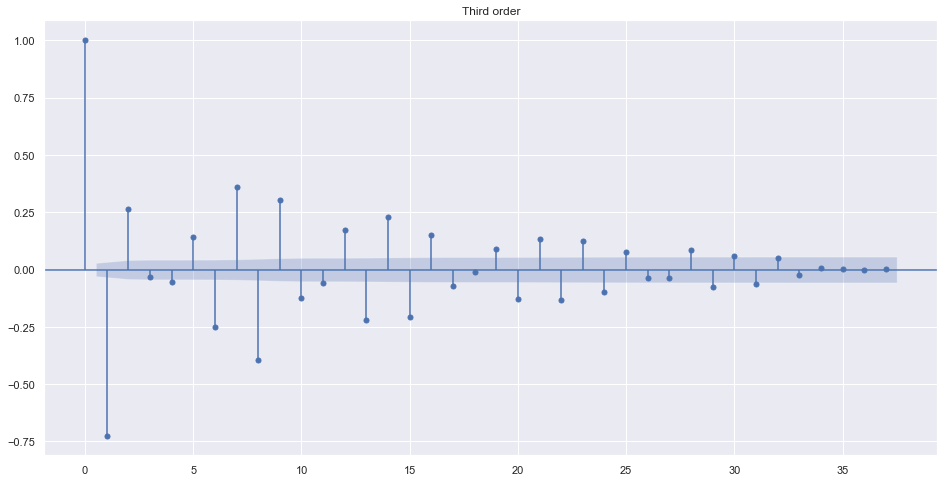
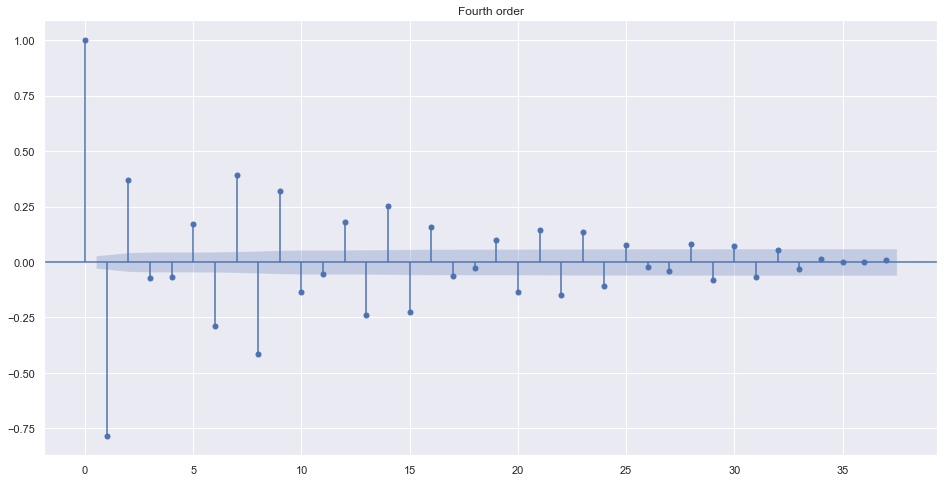
Alternatively, we can find best order by looking into ndiffs from pmdarima. It uses different algorithms to make data stationary.
from pmdarima.arima.utils import ndiffs
# adf
print(ndiffs(train.adj_close, test='adf') )
# KPSS test
print(ndiffs(train.adj_close, test='kpss') )
# PP test:
print(ndiffs(train.adj_close, test='pp') )1
1
1Grid Search
We will find best order of p,d,q in ARIMA(p,d,q) using GridSearch by manually trying each order and taking the best model as that which have very little AIC (Akaike Information Criterion).
from statsmodels.tsa.arima_model import ARIMA
import numpy as np
best_aic = np.inf
best_order = None
best_mdl = None
pq_rng = range(5)
d_rng = range(3)
for i in pq_rng:
for d in d_rng:
for j in pq_rng:
try:
tmp_mdl = ARIMA(train.adj_close, order=(i,d,j)).fit(method='mle', trend='nc')
tmp_aic = tmp_mdl.aic
print(f"Order: {(i, d, j)} AIC: {tmp_aic}")
if tmp_aic < best_aic:
best_aic = tmp_aic
best_order = (i, d, j)
best_mdl = tmp_mdl
except: continue
print('aic: {:6.5f} | order: {}'.format(best_aic, best_order))
Order: (0, 0, 1) AIC: 35649.957536726
Order: (0, 0, 2) AIC: 30452.926279850846
Order: (0, 0, 3) AIC: 25568.02974006658
Order: (0, 0, 4) AIC: 23135.908151069194
Order: (0, 1, 1) AIC: 6113.786234527973
Order: (0, 1, 2) AIC: 6103.676229595621
Order: (0, 1, 3) AIC: 6105.164302350337
Order: (0, 1, 4) AIC: 6107.097404802813
Order: (0, 2, 1) AIC: 6279.333482578022
Order: (0, 2, 2) AIC: 6116.57706331723
Order: (0, 2, 3) AIC: 6107.231252247981
Order: (0, 2, 4) AIC: 6108.574009581484
Order: (1, 0, 0) AIC: 6286.055625234081
Order: (1, 1, 0) AIC: 6102.620679110958
Order: (1, 1, 1) AIC: 6103.588554384392
Order: (1, 1, 2) AIC: 6062.107525235468
Order: (1, 1, 3) AIC: 6025.035860265804
Order: (1, 1, 4) AIC: 6010.0475679855035
Order: (1, 2, 0) AIC: 8186.521128276045
Order: (1, 2, 1) AIC: 6105.782414442538
Order: (1, 2, 3) AIC: 6064.5909315706185
Order: (1, 2, 4) AIC: 6028.885354842478
Order: (2, 0, 0) AIC: 6114.971431245766
Order: (2, 1, 0) AIC: 6103.477381158474
Order: (2, 1, 1) AIC: 6022.377015689852
Order: (2, 1, 2) AIC: 5760.708197093179
Order: (2, 1, 3) AIC: 5757.064480023204
Order: (2, 1, 4) AIC: 5730.498097448992
Order: (2, 2, 0) AIC: 7494.63308055631
Order: (2, 2, 1) AIC: 6106.877059300763
Order: (2, 2, 2) AIC: 6024.98016765312
Order: (2, 2, 3) AIC: 5765.884270710813
Order: (2, 2, 4) AIC: 5761.035898560531
Order: (3, 0, 0) AIC: 6115.823336513856
Order: (3, 1, 0) AIC: 6105.167397240131
Order: (3, 1, 1) AIC: 5991.37372259965
Order: (3, 1, 2) AIC: 5758.0483590846325
Order: (3, 1, 3) AIC: 5761.908569933521
Order: (3, 1, 4) AIC: 5753.150426707316
Order: (3, 2, 0) AIC: 7197.488347782065
Order: (3, 2, 1) AIC: 6108.672772554836
Order: (3, 2, 2) AIC: 5995.295668276515
Order: (3, 2, 3) AIC: 5762.135834467263
Order: (3, 2, 4) AIC: 5756.864902029758
Order: (4, 0, 0) AIC: 6117.512002741951
Order: (4, 1, 0) AIC: 6105.494823494794
Order: (4, 1, 1) AIC: 5962.014235342666
Order: (4, 1, 2) AIC: 5729.617168795675
Order: (4, 1, 3) AIC: 5755.675520221222
Order: (4, 1, 4) AIC: 5724.10687968731
Order: (4, 2, 0) AIC: 6871.860230500325
Order: (4, 2, 1) AIC: 6108.71314094866
Order: (4, 2, 2) AIC: 5964.708773988523
Order: (4, 2, 3) AIC: 5732.423313869451
Order: (4, 2, 4) AIC: 5736.016922455731
aic: 5724.10688 | order: (4, 1, 4)fitted = best_mdl.predict(start=best_order[1], end=len(train))
index_of_fc = train.adj_close.index
fseries = pd.Series(fitted, index=index_of_fc)
#plot
plt.figure(figsize=(20, 10), dpi=100)
plt.plot(train.adj_close, label="Train Actual", color="darkgreen")
plt.plot(fseries, label="Train Forecast", color="darkred")
prd=rrresults1.forecast(steps=len(test))[0]
prd = pd.Series(prd, index=test.index)
plt.plot(test.adj_close, label="Test Actual")
plt.plot(prd, label="Test Predicted")
plt.title(f"ARIMA{best_order} VS Actual")
plt.legend(["Train True", "Train Predicted", "Test True", "Test Predicted"])
plt.show()
# plt.legend(loc='upper left', fontsize=15)
# plt.title(f"ARMA({(p,q)}) Value Performance")
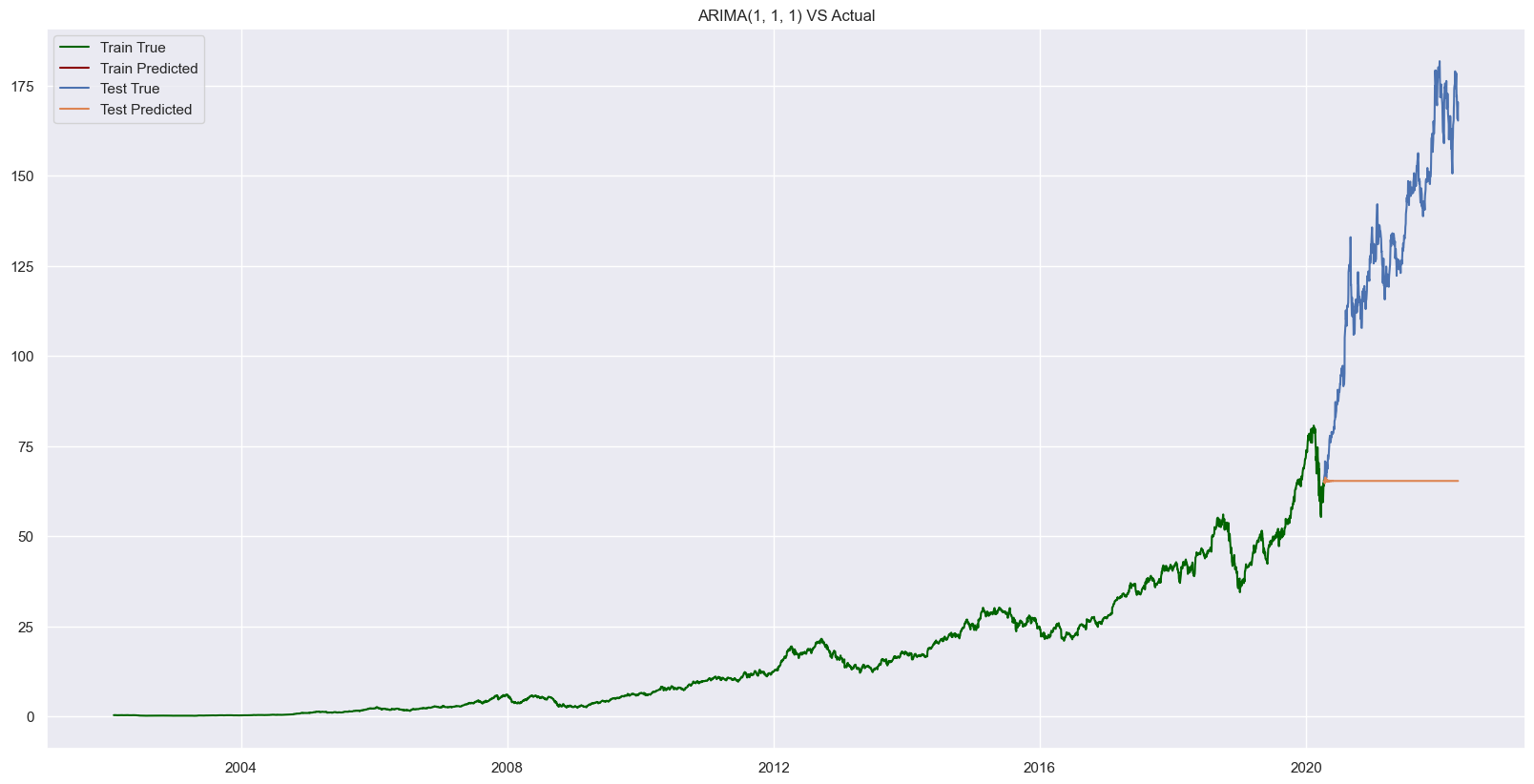
percentage_change(fseries, train.adj_close), percentage_change(prd, test.adj_close)(0.0, 0.03339882121807466)Our ARIMA Model did not perform well in forecasting. Lets try to train a SARIMA Model.
Seasonal ARIMA (SARIMA)
Take seasonality when fitting a model. Use orders already found from previous steps. This model uses seasonal component also.
- SARIMA(p, d, q)(P, D, Q, M)
- D = 0 for stationary data, else the differencing value that makes data stationary.
- P from PACF and Q from ACF.
- The value of M should be chosen from Seasonal Decompose graph.
We know from the ARIMA that best order is (4,1,4) lets use that to find best seasonal parameters.
# check for weekly data
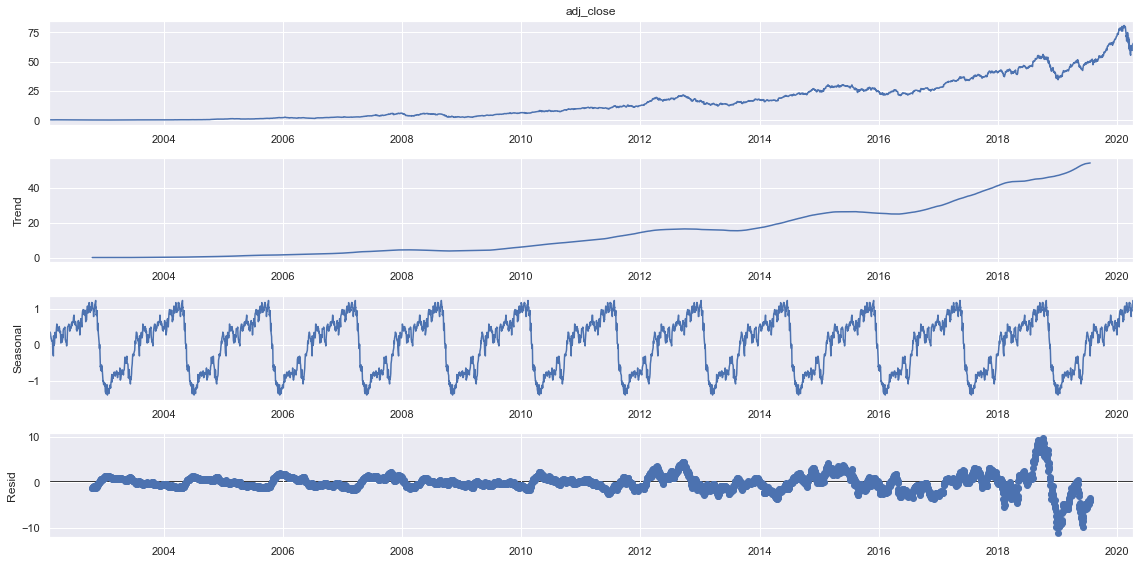
from statsmodels.tsa.seasonal import seasonal_decompose
sdec = seasonal_decompose(train.adj_close, model="additive", period=365)
sdec.plot()
plt.show()
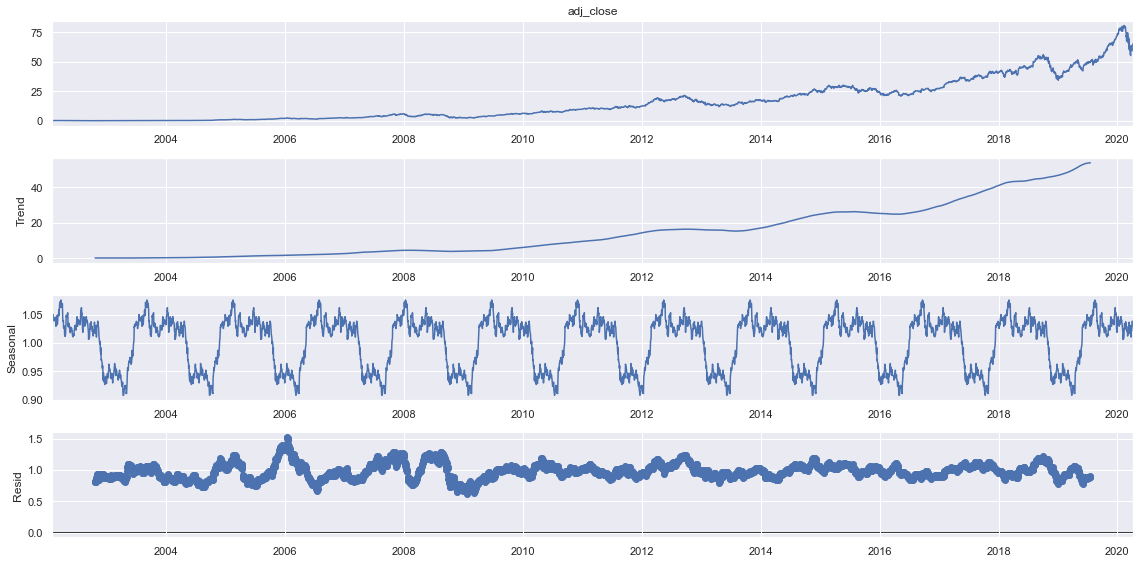
sdec = seasonal_decompose(train.adj_close, model="multiplicative", period=365)
sdec.plot()
plt.show()
from statsmodels.tsa.statespace.sarimax import SARIMAX
order = (4, 1, 4)
best_aic = np.inf
best_mdl = None
ms=[365]
best_order = None
best_sorder = None
for P in range(3):
for Q in range(3):
for D in range(3):
for m in ms:
try:
sorder = (P, D, Q, m)
# define a model
smodel = SARIMAX(train.adj_close, order=order, seasonal_order=sorder)
smodel = smodel.fit()
print(f"Order: {order}, Sorder: {sorder}, AIC: {smodel.aic}")
if smodel.aic<best_aic:
best_aic = smodel.aic
best_mdl = smodel
best_order = order
best_sorder = sorder
except Exception as e:
print(e)
# continue
print(f"Best Order: {best_order} Best SOrder: {best_sorder} AIC: {best_mdl.aic}")Order: (4, 1, 4), Sorder: (0, 0, 0, 365), AIC: 5750.778071206555
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
KeyboardInterrupt: It will take a lot time and will not even find best order. SO, lets use monthly average data instead of daily.
Using Monthly Average instead of Daily Data
import pmdarima as pm
mtrain=train.resample("1M").adj_close.mean()
mtest = test.resample("1M").adj_close.mean()
model=pm.auto_arima(mtrain, start_p=0, start_q=0,
max_p=5, max_q=5, m=12,
start_P=0, seasonal=True,stationary=False,
d=1, D=1, trace=True,
error_action='ignore', # don't want to know if an order does not work
suppress_warnings=True, maxiter=50) Performing stepwise search to minimize aic
ARIMA(0,1,0)(0,1,1)[12] : AIC=inf, Time=0.47 sec
ARIMA(0,1,0)(0,1,0)[12] : AIC=982.844, Time=0.03 sec
ARIMA(1,1,0)(1,1,0)[12] : AIC=874.988, Time=0.28 sec
ARIMA(0,1,1)(0,1,1)[12] : AIC=inf, Time=0.83 sec
ARIMA(1,1,0)(0,1,0)[12] : AIC=946.930, Time=0.04 sec
ARIMA(1,1,0)(2,1,0)[12] : AIC=851.648, Time=0.37 sec
ARIMA(1,1,0)(2,1,1)[12] : AIC=830.994, Time=2.03 sec
ARIMA(1,1,0)(1,1,1)[12] : AIC=830.031, Time=0.31 sec
ARIMA(1,1,0)(0,1,1)[12] : AIC=inf, Time=0.61 sec
ARIMA(1,1,0)(1,1,2)[12] : AIC=830.257, Time=1.78 sec
ARIMA(1,1,0)(0,1,2)[12] : AIC=828.257, Time=0.73 sec
ARIMA(0,1,0)(0,1,2)[12] : AIC=841.816, Time=0.52 sec
ARIMA(2,1,0)(0,1,2)[12] : AIC=821.246, Time=1.01 sec
ARIMA(2,1,0)(0,1,1)[12] : AIC=inf, Time=0.90 sec
ARIMA(2,1,0)(1,1,2)[12] : AIC=823.234, Time=2.12 sec
ARIMA(2,1,0)(1,1,1)[12] : AIC=824.653, Time=0.59 sec
ARIMA(3,1,0)(0,1,2)[12] : AIC=822.891, Time=1.09 sec
ARIMA(2,1,1)(0,1,2)[12] : AIC=812.199, Time=2.64 sec
ARIMA(2,1,1)(0,1,1)[12] : AIC=inf, Time=0.83 sec
ARIMA(2,1,1)(1,1,2)[12] : AIC=814.068, Time=4.27 sec
ARIMA(2,1,1)(1,1,1)[12] : AIC=814.260, Time=1.52 sec
ARIMA(1,1,1)(0,1,2)[12] : AIC=811.256, Time=1.50 sec
ARIMA(1,1,1)(0,1,1)[12] : AIC=inf, Time=0.78 sec
ARIMA(1,1,1)(1,1,2)[12] : AIC=813.041, Time=2.93 sec
ARIMA(1,1,1)(1,1,1)[12] : AIC=813.519, Time=1.56 sec
ARIMA(0,1,1)(0,1,2)[12] : AIC=821.365, Time=1.25 sec
ARIMA(1,1,2)(0,1,2)[12] : AIC=811.824, Time=3.98 sec
ARIMA(0,1,2)(0,1,2)[12] : AIC=817.334, Time=1.53 sec
ARIMA(2,1,2)(0,1,2)[12] : AIC=815.090, Time=5.30 sec
ARIMA(1,1,1)(0,1,2)[12] intercept : AIC=808.813, Time=4.43 sec
ARIMA(1,1,1)(0,1,1)[12] intercept : AIC=inf, Time=2.13 sec
ARIMA(1,1,1)(1,1,2)[12] intercept : AIC=810.269, Time=5.39 sec
ARIMA(1,1,1)(1,1,1)[12] intercept : AIC=inf, Time=3.07 sec
ARIMA(0,1,1)(0,1,2)[12] intercept : AIC=820.084, Time=1.75 sec
ARIMA(1,1,0)(0,1,2)[12] intercept : AIC=827.189, Time=1.63 sec
ARIMA(2,1,1)(0,1,2)[12] intercept : AIC=810.401, Time=5.25 sec
ARIMA(1,1,2)(0,1,2)[12] intercept : AIC=815.022, Time=5.47 sec
ARIMA(0,1,0)(0,1,2)[12] intercept : AIC=838.364, Time=1.55 sec
ARIMA(0,1,2)(0,1,2)[12] intercept : AIC=813.281, Time=1.96 sec
ARIMA(2,1,0)(0,1,2)[12] intercept : AIC=817.661, Time=2.27 sec
ARIMA(2,1,2)(0,1,2)[12] intercept : AIC=inf, Time=8.56 sec
Best model: ARIMA(1,1,1)(0,1,2)[12] intercept
Total fit time: 85.290 seconds# Forecast
n_periods = len(mtest)
fc, confint = model.predict(n_periods=n_periods, return_conf_int=True)
index_of_fc = mtest.index
# make series for plotting purpose
fc_series = pd.Series(fc, index=index_of_fc)
lower_series = pd.Series(confint[:, 0], index=index_of_fc)
upper_series = pd.Series(confint[:, 1], index=index_of_fc)
t = mtest
t.index = index_of_fc
# Plot
plt.plot(t)
plt.plot(fc_series, color='darkgreen')
plt.fill_between(lower_series.index,
lower_series,
upper_series,
color='k', alpha=.15)
plt.legend(["Real Data", "Forecasted"])
plt.title("AAPL Forecast")
plt.show()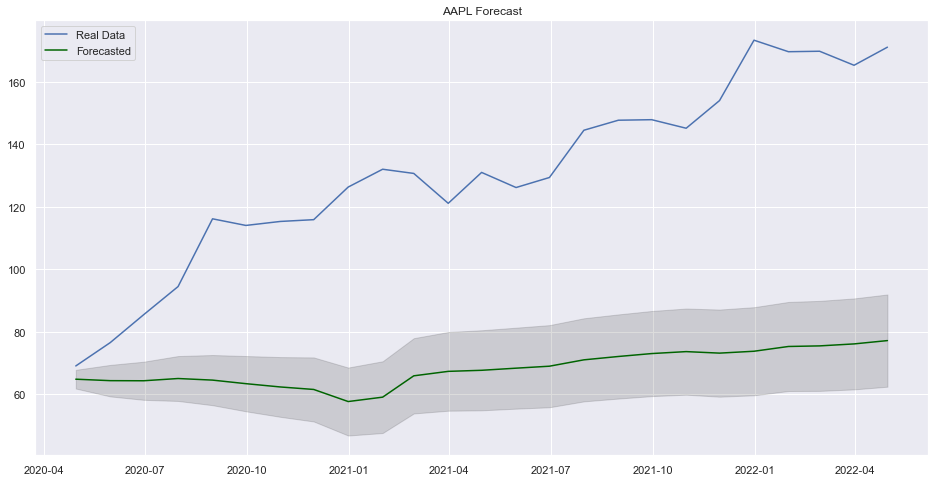
Conclusion
It seems that our model was able to find some pattern in the test data but it is not near to be good. Using different level of date might be a best idea in this case.